Multiple Intelligences and Artificial Intelligence
Natural Language Processing and Deep Learning
Camellia on September, 26th, 2019
Today, Camellia introduces Linguistics Intelligence Technologies in Artificial Intelligence:
Computational Linguistics
+ Development
+ Structure
+ Production
+ Comprehension
Machine Learning and Deep Learning
+ Machine Learning
+ Artificial Neural Networks
Natural Language Processing
+ Linguistics
+ Functions
+ Steps
+ Word2Vec
+ Parse
+ Recurrent Neural Networks
+ Convolutional Neural Networks
Hardware
Instinct Intelligence

How does a Robot, a Droid, or an Autopilot car talk with us?
What's the cutting edge technology help Artificial Intelligence Machines to speak, listen, write and read?
Computational Linguistics
Computational Linguistics is an interdisciplinary field concerned with the statistical or rule-based modelling of natural language from a computational perspective. Traditionally, computational linguistics was usually performed by computer scientists who had specialised in the application of computers to the processing of a natural language.
Four issues are being studied in Computational linguistics.

Developmental Linguistics
Language is a cognitive skill which develops throughout the life of an individual. Languages themselves also change and evolve through time. Every year, a lot of cyber neologisms borning from the Internet or Social Medias are edited in the Oxford Dictionary. Robots need to continue developing its linguistics, and in the future to help human to predict linguistic evolution based on their superintelligence.

The first step in Computational Linguistics is modelling human language. It is the model that Artificial Intelligence Machines can only identify. Now, two typical ways, such as Statistical Grammar and Connectionist Model, are used to modelling.

Statistical grammar is a grammar framework with a probabilistic notion of grammaticality. Statistical natural language processing uses statistical, probabilistic and stochastic methods, especially to resolve difficulties that arise because longer sentences are highly ambiguous when processed with realistic grammars, yielding thousands or millions of possible analyses.
The difference between statistical and stochastic is that stochastic is more related to the time factor.
A probabilistic model consists of a non-probabilistic model plus some numerical quantities. The technology for statistical natural language comes mainly from machine learning and data mining, both of which are fields of artificial intelligence that involve learning from data.
A Connectionist Model was created based on an affordance model in which mappings between actions, perceptions, and effects were created and linked to spoken words.
It is important to note that this information could only have been empirically tested using a computational approach.
Structural Linguistics
To create better computational models of language, an understanding of language's structure is crucial. One of the essential pieces of being able to study linguistic structure is the availability of large linguistic corpora or samples. This helps computational linguists the raw data necessary to run their models and gain a better understanding of the underlying structures present in the vast amount of data which is contained in any single language. However, the raw data or samples should be pre-processed:
+ Annotation - includes structural markup, part-of-speech tagging, parsing, and numerous other representations.
+ Abstraction - typically includes linguist-directed search but may consist of, e.g., rule-learning for parsers.
+ Analysis - might include statistical evaluations, optimisation of rule-bases or knowledge discovery methods
Treebank is a parsed text corpus that annotates syntactic or semantic sentence structure. This is because both the syntactic and semantic structure is commonly represented compositionally as a tree structure.
A Semantic Treebank is a collection of natural language sentences annotated with a meaning representation. These resources use a formal description of each sentence's semantic structure. Semantic treebanks vary in the depth of their semantic representation.
A Syntax Treebank is a treebank lying at the interface between syntax and semantics, where the representation structure can be interpreted as a graph, representing the subject of infinitival phrases, extraction, it-clef construction, shared subject ellipsis and so on.
More knowledge of Linguistics, better model of Computational Linguistics!
Linguistic Production and Comprehension
Camellia talks about Linguistic Production and Linguistic Comprehension together as they are a feedback loop. We need interactive ways, so do the Artificial Intelligence Machines.
Recent technologies have placed more of an emphasis on speech-based interactive systems. These systems, such as Siri of the iOS, operate on a similar pattern-recognising technique as that of text-based systems, but with the former, the user input is conducted through speech recognition. This branch of linguistics involves the processing of the user's speech as sound waves and the interpreting of the acoustics and language patterns for the computer to recognise the input.

Using linguistic input from humans, algorithms have been constructed which are able to modify a system's style of production based on a factor such as linguistic input from a human, or more abstract elements like politeness or any of the five principal dimensions of personality: Openness to experience, Conscientiousness, Extraversion, Agreeableness, Neuroticism. This work takes a computational approach via parameter estimation models to categorise the vast array of linguistic styles we see across individuals and simplify it for a computer to work in the same way, making human-computer interaction much more natural.

Machine Learning
These four issues in Computational linguistics, machine learning techniques are used in Development, Production and Comprehension. Machine Learning is one of the most critical technologies in Artificial Intelligence.
Four learning methods are used:

Supervise
Artificial Intelligence Machines need teachers too. Human is their teacher when they are learning. Input data or information into models embedded in Artificial Intelligence Machines, forward calculate by models, and output data is got.
Calculate by models, and output data is got.
As a teacher, we know the precise output data of the input data. Just compare the accurate data and the output data of models. The different value is propagated back, and models update parameters inside themselves. Again, a new set of input, a new forward calculation, a new set of output, and another update based on the new different values... Not until the different value is closed to zero, Artificial Intelligence Machines stop learning. However, this stop does not mean a robustness model.
Un-supervise
Just as its name implies, Artificial Intelligence Machines study by themselves, no teacher, no instruction. They map the input information or cluster the input information to a collection of new information or data. Then the new collection is evaluated with some rules. The same to backpropagation in Supervise Learning. Parameters in Models are updated. Again and again, until the evaluated result is lovely.
Semi-Supervise
As the child of Supervise Learning and Un-supervise Learning, Semi-Supervise Learning process part of models' parameters based on the different value between the accurate data and the output data of models, and process part of models' parameters with mapping and clustering.
Reinforcement Learning
This time, Artificial Intelligence Machines study in a comprehensive circumstance. They collect information actively and make a response. The circumstance also gives feedback based on Artificial Intelligence Machines' response. The feedback from the circumstance is the evaluated rule. After many information exchanges interactively, Artificial Intelligence Machines know how to make circumstance happy.
Machine Learning make Artificial Intelligence Machines model by themselves possible. There are two typical modelling ways. One is Ruled Based System; the other is Machine Learning. Representation Learning is a junior student in Machine Learning which gets Features from input data or information. While Deep Learning is an excellent student in Representation Learning which not only gets typical Features but also makes more abstract Features. Thus Deep Learning could do more sophisticated tasks.
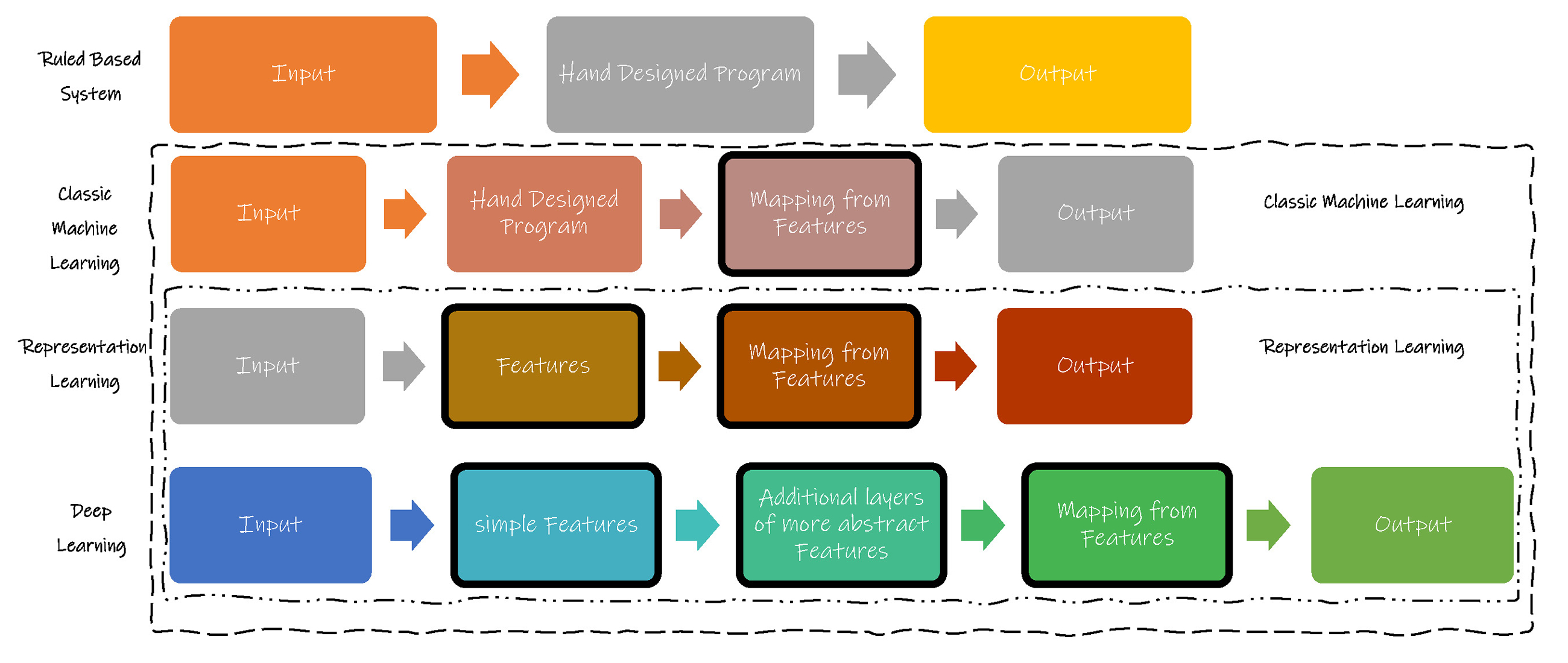
Deep Learning
Deep Learning is just a type of Machine Learning or more exactly Representation Learning which is using sophisticated Artificial Neural Network Models and is learning all time.
Artificial Neural Networks
The technology of Artificial Neural Networks originates from human brain neuro working philosophy. Each node in the Artificial Neural Network has some connectors connecting other nodes. Thus the node receives input information send from some nodes and again sent out output information to other nodes. The output information is a result of calculating the input information. All notes construct an artificial brain.
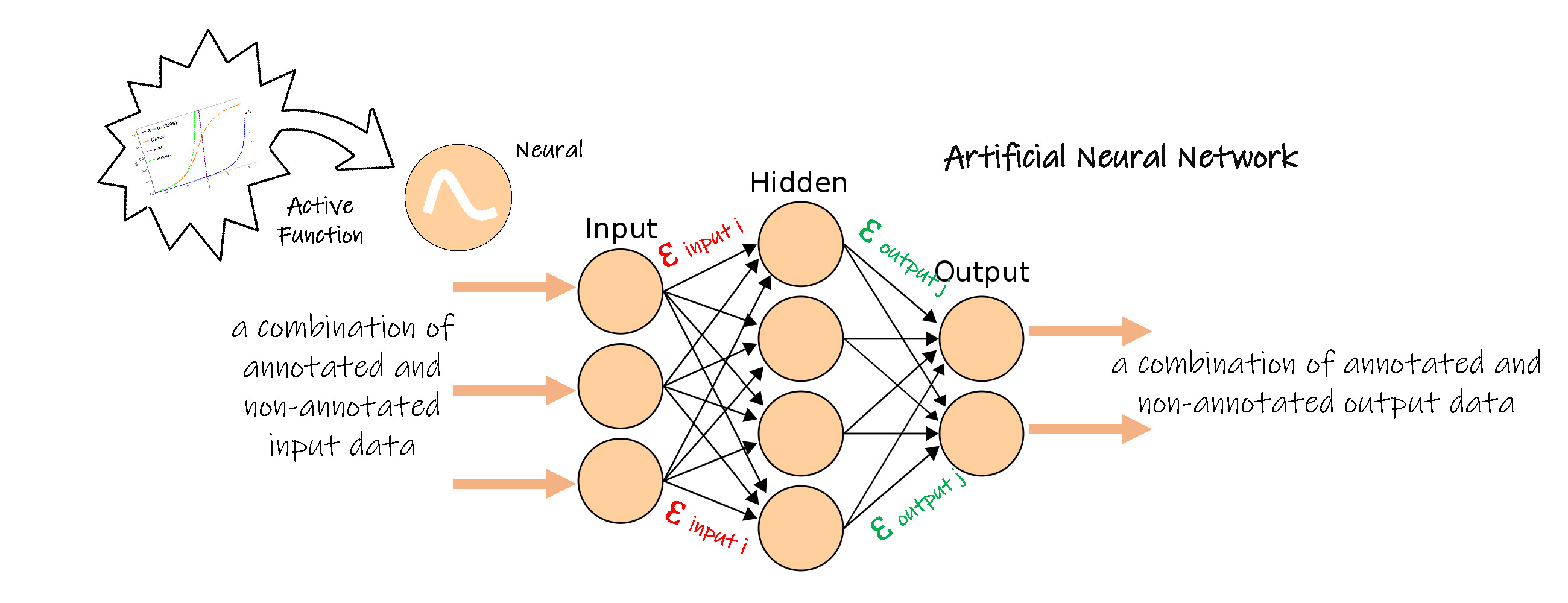
Each node is a neuro. The first set of nodes get information from outsides, and they are called Input Layer. There is an active function inside these nodes. The input information is calculated based on the active function, and the result is sent to the next set of nodes ( Hidden Layer ).
The node in Hidden Layer gets the output information from all of part of nodes in Input Layer. However, the output information of the Input Layer node should multiply a Weight in the connector before going into the Hidden Layer. That means Hidden Layer nodes add all its multiplied input information and calculate the sum value based on the active function, to get its output information. Then the Hiden Layer output information is sent to the next set of nodes ( Output Layer ).
The same to Hidden Layer, each Output Layer node adds all its multiplied input information and do a new calculate. The output information of the Output Laye node is the output of the whole model.
Typically, we could build more than one Hidden Layer.
Building this model is a learning process. Artificial Neural Network could do Supervise Learning, Un-supervise Learning, Semi-supervise Learning and Reinforcement Learning.
Let us do a Supervise Learning.
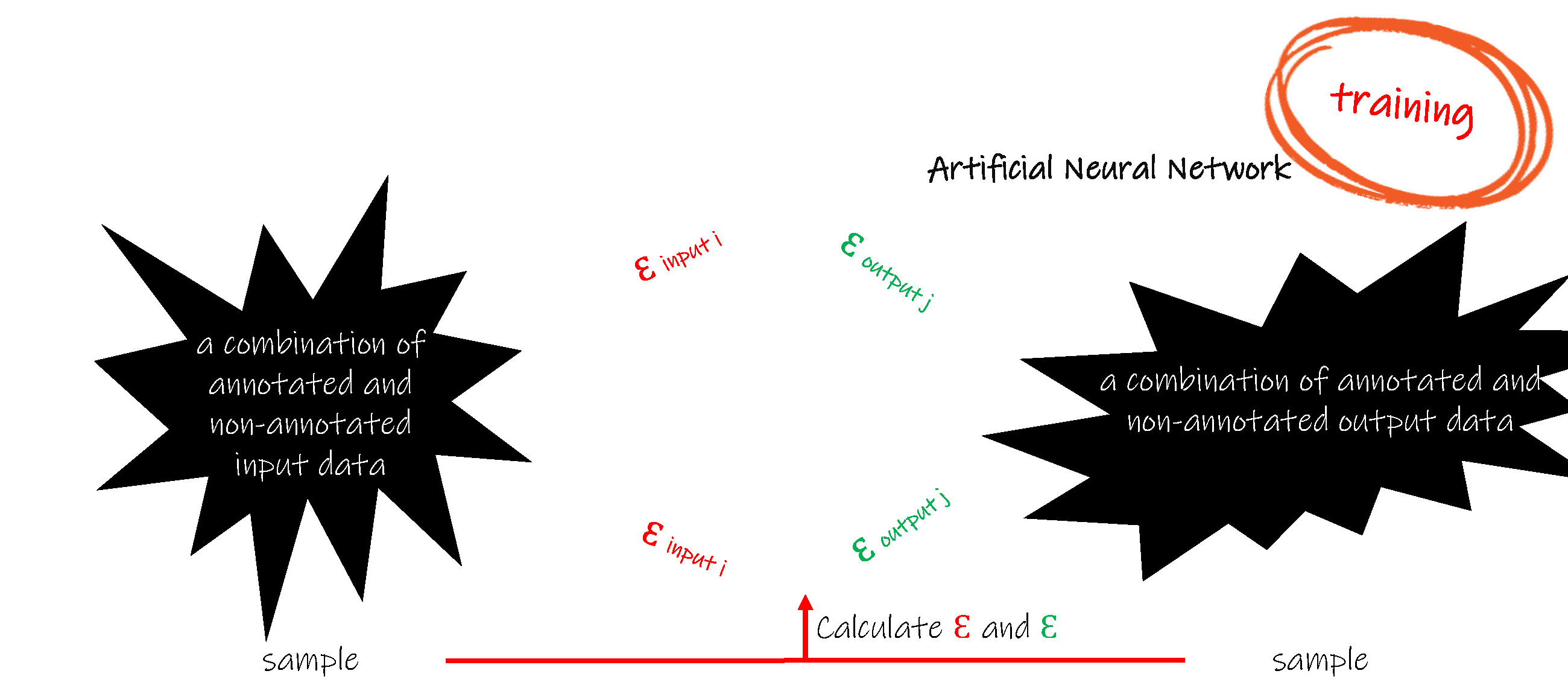
We collect a set of input data and output data. They are called Traning Sample. In the training sample, the output data has the right relationship with the input data. Thus we call the input data “annotated”.
The annotated input data is input to the Artificial Neural Network. Learning begins. The Forward calculation is doing inside this Model. Then compare the output data of the model to the output data in the training sample. The difference value, which is also called errors, will be propagated backwords. During the backpropagation, all weights inside the connectors will be updated.
Again, do next forward calculation, get new errors, do next backpropagation and update weights.
…
Not until the error is close to zero, the learning will not stop.
However be aware, the error value closed to zero does not always mean a good result. Maybe we get the minimum error value only in local scope, not the whole range.
The main aim is updating weights during learning. However, in order to do the first forward calculation, all Weights should be initialized firstly. How to initial Weights is very important. Just as the training sample, the initialled Weight should be as diverse as possible.
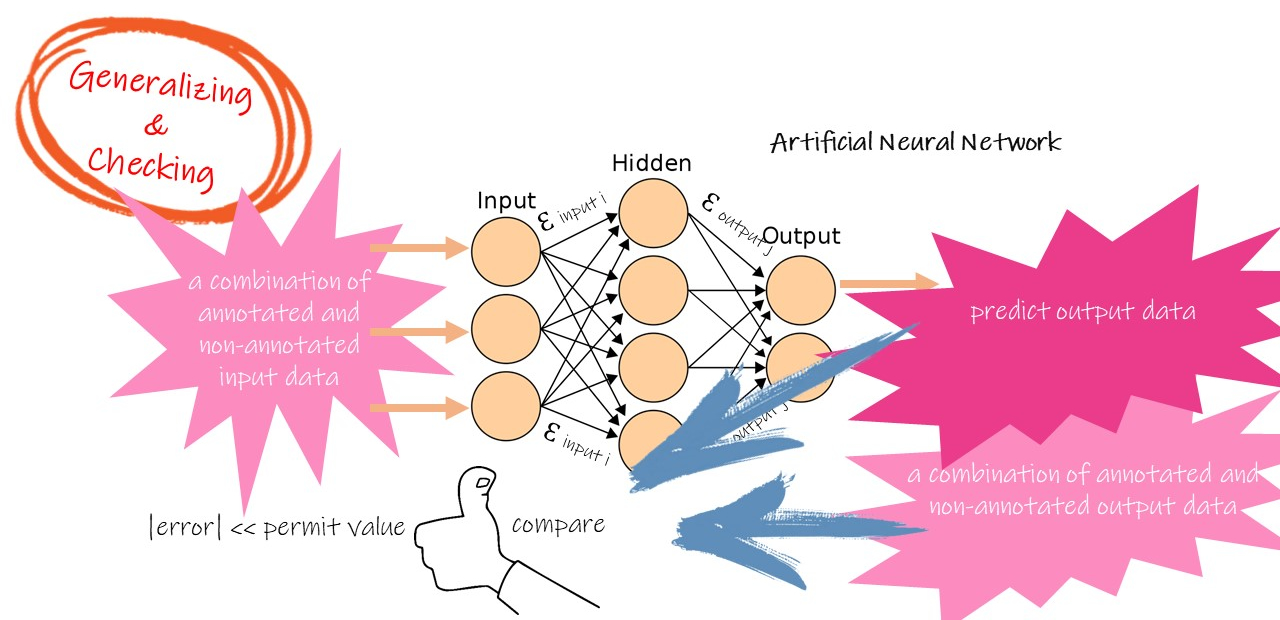
Now we use some new input data which is in the training sample but is not used during the training process, to do a new forward calculation - also - calculating the different values between model output and the output in training sample. If the difference value is close to zero, we could primarily say that modelling success.
This process is called Generalising and Checking.


The undergraduate needs to pass some exam before getting a degree. The Generalization and Checking is a test too. When getting a good score, the model could go to work formally.
Now the unannotated input data is input data, and we don't know the correct output data, which has the relationship with the input data. Just use the model to calculate the output data.

Nevertheless a graduate had very high scores when in university may not perform well on his/her job. Thus the model should also learn even it is working. Work and learn together; the model will get new features of information.
Artificial Neural Network Technology has a long history. However, due to the poor efficiency of computer hardware and training sample is scarce before 2000, it is not widely used.
In the past ten years, computer technology advanced very quickly, and the state of art CPU and GPU both had terrific performance. Deep Learning is not simple to implement, as it requires large amounts of data and substantial computing power. Using a CPU is rarely enough, and recent advancements have made the use of a GPU ( Graphics Processing Unit ) much faster. Now there are even TPUs (Tensor Processing Units), specifically designed to speed up things.
These accelerate the training process of Artificial Neural Network Models.
Besides, Internet, High capacity Memory and Cloud Storage Technology, and Mobile Phone make data collection more effient and provide more diverse training sample to models. All build a sophisticate Artificial Neural Network model with many Hidden Layers. All make Artificial Neural Network models do difficult tasks.
Several deep learning frameworks can be used by people with little experience with machine learning technology, or even with no experience at all. With the help of these frameworks, you can upload your data and train a deep learning model to perform state-of-the-art deep learning with little effort.

TensorFlow was created by Google and is one of the most popular deep learning frameworks. It is used by major corporations like Airbnb, Intel, and Twitter. Most of the Google technologies are allegedly relying on it. For instance, Google Translate is using TensorFlow capabilities such as natural language processing; text classification and summarisation; speech, image and handwriting recognition; forecasting; and tagging. TensorFlow is a Python-based, open-source deep learning framework which is still supported by Google.
Keras is another open-source deep learning framework that is widely used. Keras means the Gate of Horn which originated in the Greek language, in which the word for "horn" is similar to that for "fulfil". But Keras was built on TensorFlow and ultimately reached something TF was terrible at – Keras is remarkably simple to use. That's why Keras was integrated into TensorFlow. It requires very little code and is one of the most accessible frameworks for beginners to work with.
Caffe is an open-source deep learning framework known for its speed. It can process more than 60 million images a day, making it very suitable for image recognition. It works with C, C++, Python, MATLAB, and CLI. Its expressive architecture allows for training neural nets without hard coding, and its extensible code encourages active development. Caffe is popular with deep visual recognition applications.
PyTorch is relatively new but is gaining popularity. It is also open-source, primarily developed by Facebook, and is known for its simplicity, flexibility, and customizability. PyTorch is built with a clean architectural style, making the process of training and developing deep learning models easy to learn and execute.
Previously known as CNTK, Microsoft Cognitive Toolkit is an open-source deep learning framework to train deep learning models. It can efficiently train CNNs and RNNs for almost any DL task, including image, speech and text-based analysis. It is supported by interfaces such as Python, C++, and CLI. Microsoft Cognitive Toolkit provides higher performance. Microsoft Cognitive Toolkit is capable of handling images, handwriting, and speech recognition problems.
Natural Language Processing
If we want to have computers achieve the same level of skills to acquire new information, then we start by modelling how humans communicate, person to person, and how they acquire new information and context just by talking. Thus, without any technical ability, as long as you can bring that nuanced human insight to a role, you can be successful.

Linguistics
The first step of development Natural Language Processing Technology is to review our human language, that is Linguistics. The five main components of language are phonemes, morphemes, lexemes, syntax, and context. Along with semantics and pragmatics, these components work together to create meaningful communication among individuals.
If you have linguistics and programming skills, that's a killer combination, and those tech skills are always welcome, but we've all ended up learning a lot of technical and programming skills just by working so closely with our software development and engineering teams.
。

Phonemes are the basic unit of phonology. It is the smallest unit of sound that may cause a change of meaning within a language, but that doesn’t have meaning by itself. There are Phonetics and Phonology. These two heavily overlapping subfields cover all the sounds that humans can make, as well as which sounds make up different languages.

Phonetics deals with the organs of sound production. The organs of the sound output are mouth, tongue, throat, nose, lips and the palate. From these organs or parts in the mouth, various sounds are produced. These sounds are called as gutturals, palatals, cerebrals, dentals, and labials. Gutturals are produced in the throat, palatals are produced from the palate, cerebrals are produced at the roof of the palate, dentals from teeth, and labials from lips.

Phonology, on the other hand, deals with the sounds and their changes due to various factors such as climatic change, race, the influence of other languages and the like. There are numerous sound changes such as diphthongisation, palatalisation, metathesis, anaptyxis, apocope, syncope, vowel breaking, haplology, assimilation, dissimilation, and the like. It is interesting to note that phonology plays a vital role in the study of languages or linguistics. This is due to the fact that phonology paves the way or lays the foundation for morphology or word building.
Base on the study of Phoneme, voice recognising is a process of transform sound wave into words, and vice versa, to transform words into sound is sound production.
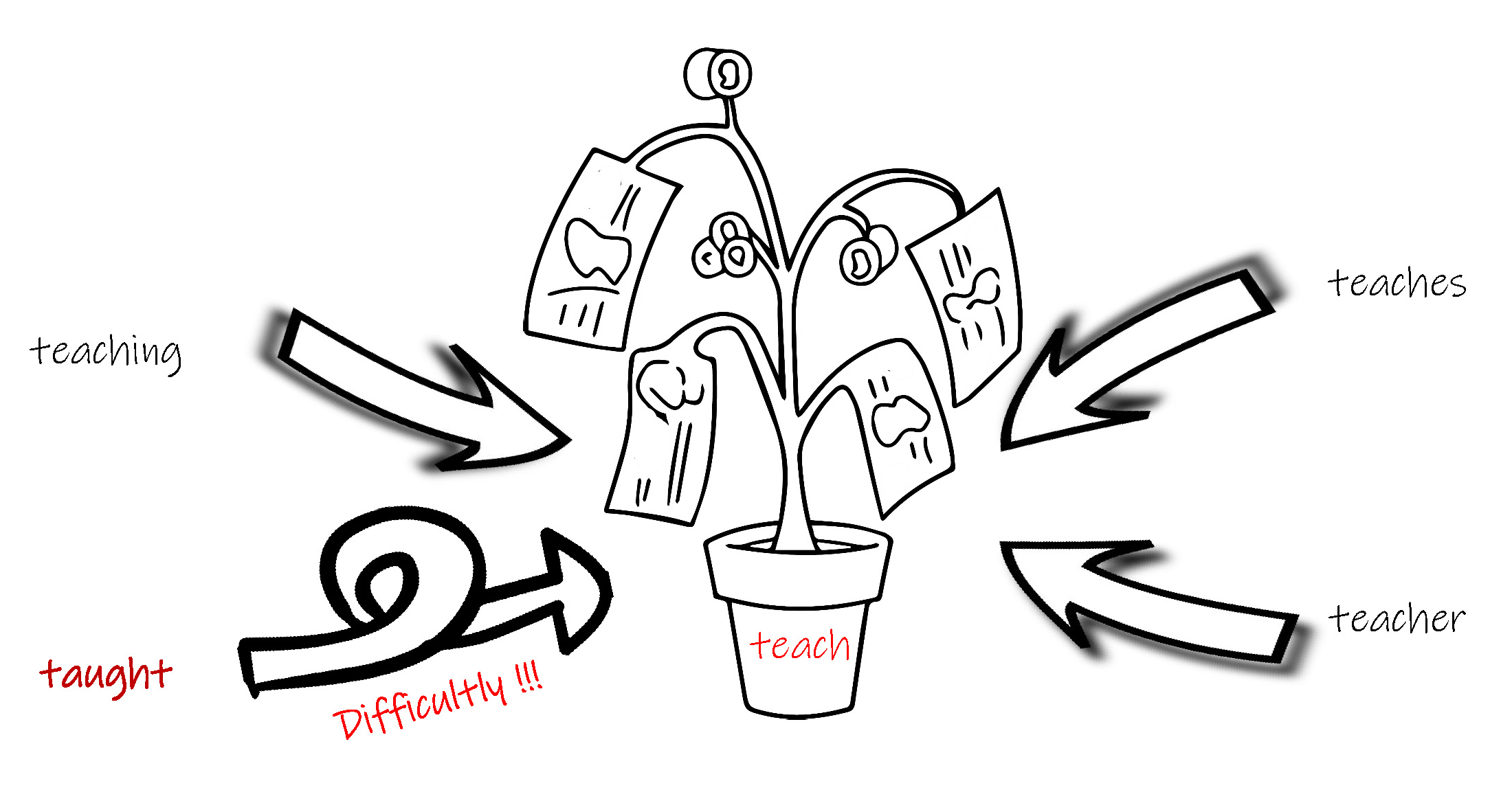
Morphemes the basic unit of morphology, are the smallest meaningful unit of language. Thus, a morpheme is a series of phonemes that has a special meaning. If a morpheme is altered in any way, the entire meaning of the word can be changed. Some morphemes are individual words (such as "teach"). These are known as free morphemes because they can exist on their own. Other morphemes are prefixes, suffixes, or other linguistic pieces that aren't full words on their own but do affect meaning (such as the "-er" at the end of "teacher" or the "-s" at the end of "teachers" ) Because these morphemes must be attached to another word to have meaning, they are called bound morphemes.
Lexeme is the set of inflected forms taken by a single word. For example, members of the lexeme TEACH includes "teaches", "taught", and "teaching". This lexeme excludes "teacher" (a derived term—it has a derivational morpheme attached).
Syntax is a set of rules for constructing full sentences out of words and phrases.

Every language has a different set of syntactic rules, but all languages have some form of syntax.
In English, Word order matters means. In languages like Finnish, word order doesn’t matter for general meaning—different word orders are used to emphasise different parts of the sentence.
Context is how everything within language works together to convey a particular meaning. Context includes tone of voice, body language, and the words being used. Depending on how a person says something, holds his or her body or emphasises certain points of a sentence, a variety of different messages can be conveyed.

For example, the word "awesome", when said with a big smile, means the person is excited about a situation. "awesome" said with crossed arms, rolled eyes, and a sarcastic tone means the person is not thrilled with the case.
Semantics most generally, is about the meanings of words and phrases, this is called lexical semantics. A key concern is how meaning attaches to larger chunks of text, possibly as a result of the composition from smaller units of meaning. This is called compositional semantics.
For example, in the sentence “Many cute bears are in Camellia Café”, “Camellia Café” is a phrase which indicates a place. They are compositional semantics.
Pragmatics acts as the basis for all language interactions and contact. It is a crucial feature to the understanding of language and the responses that follow this. Therefore, without the function of Pragmatics, there would be very little understanding of intention and meaning.

For example: Can you pass the salt?
Literal Meaning: Are you physically able to do this task?
Literal Response: Yes!
Pragmatic Meaning: Will you pass me the salt?
Pragmatic Response: Yes, with pleasure.
Another example: What time do you call this?
Literal Meaning: What time is it?
Literal Response: A time (e.g. twenty past ten).
Pragmatic Meaning: A different question entirely (e.g. Why are you so late?).
Pragmatic Response: Explain the reason for being so late.
After getting Linguistics, let's began to talk Natural Language Processing Technology.
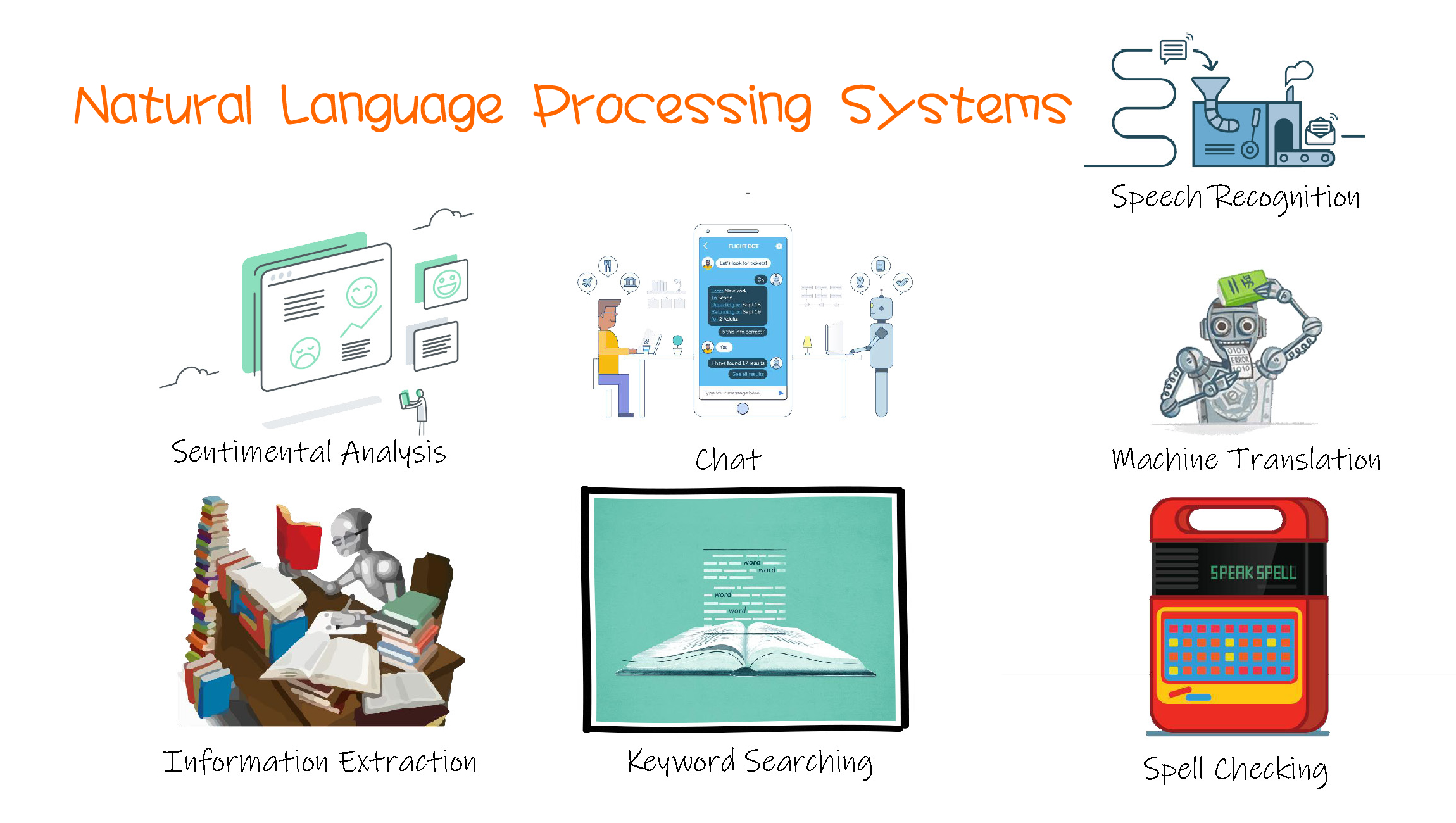
Functions
What does Natural Language Technology help us to do?
+ Machine Translation
+ Spell Checking
+ Keyword Searching
+ Information Extraction
+ Speech Recognition
+ Chat
+ Sentimental Analysis
Steps
How does an Artificial Intelligence Machine perform a Natural Language Processing task?
One type of Natural Language Processing systems was based on complex sets of hand-written rules. This is a top-down approach that combines linguistic AI with a rule-based classifier specific to used cases and expected input. This Sparse Data Approach does not require as much data to get started, and use Leverages linguistic abstractions to capture expected diversity. It is a full inspectable classifier. When an intent is misclassified, we can directly modify the logic tell it to do otherwise.

The other type is machine learning algorithms for language processing. This is called a bottom-up classifier which learns based on data from used cases, how to classify new examples. It requires large amounts of classified data, relies on that data capturing, and gets a Black Box classifier. When an intent is misclassified, new training data is needed to add to convince the classifier to do otherwise.

As longer sentences or articles are highly ambiguous when processed, yielding thousands or millions of possible analyses.
A language model aims to minimise how confused the model is having seen a given sequence of text.
Let us talk step by step:
Tokenization
Given a character sequence and a defined document unit, tokenization is the task of chopping it up into pieces, called tokens, perhaps at the same time throwing away certain characters, such as punctuation.

In Camellia likes cute bears , after doing tokenization, we get Camellia , likes , cute and bears.
In Camellia teaches in Camellia Café , we get Camellia , teaches , in , Camellia and Café . The number of words is five, while the number of types is four with only one Camellia .
A Token is an instance of a sequence of characters in some particular document that is grouped as a useful semantic unit for processing.
A Type is the class of all tokens containing the same character sequence.
Stemming
Normalize words into its base form or root form.
In English, the process of changing from teaches , teaching , teacher into teach is Stemming.
Lemmatization
Group different forms of a word.
Map several words into one common root.
Output a proper word.
This process is very close to Stemming, but Lemmatization could do more complicated tasks, such as form taught to teach.

Part-Of-Speech Tagging
Also called Grammatical Tagging or Word-Category Disambiguation, is the process of marking up a word in a text as corresponding to a particular part of speech, based on both its definition and its context—i.e., its relationship with adjacent and related words in a phrase, sentence, or paragraph.

A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, preposition, conjunction, pronoun, interjection, etc.
Once performed by hand, POS tagging is now done in the context of computational linguistics, using algorithms which associate discrete terms, as well as hidden parts of speech, following a set of descriptive tags. POS-tagging algorithms fall into two distinctive groups: rule-based and stochastic.
In Camellia loves cute bears , Camellia is a noun, loves is a verb, cute is an adjective and bears is also a noun.

POS tagging is a supervised learning solution that uses features like the previous word, next word, is first letter capitalised etc.
The most popular tag set is Penn Treebank tag set.
Named Entity Recognition
Categorise words.
In Camellia loves cute bears , Camellia is a person, and bear is an animal.
Categorise words.
In Camellia teaches in Camellia Café , Camellia is a person, and Camellia Café is one place.
Chunking
Pick up Individual pieces of Information and Group them into more significant Pieces.
Extract phrases from unstructured text.
Instead of just simple tokens which may not represent the actual meaning of the text, it's advisable to use a phrase as a single word instead of separate words.

In Camellia teaches in Camellia Café , we group Camellia and Café into Camellia Café .
This is useful for information extraction about location, name, and so on.
Model of Words

Word2Vec
The vocabulary is a vector of numbers, called tokens, where each token represents one of the unique words or punctuation symbols in our corpus.
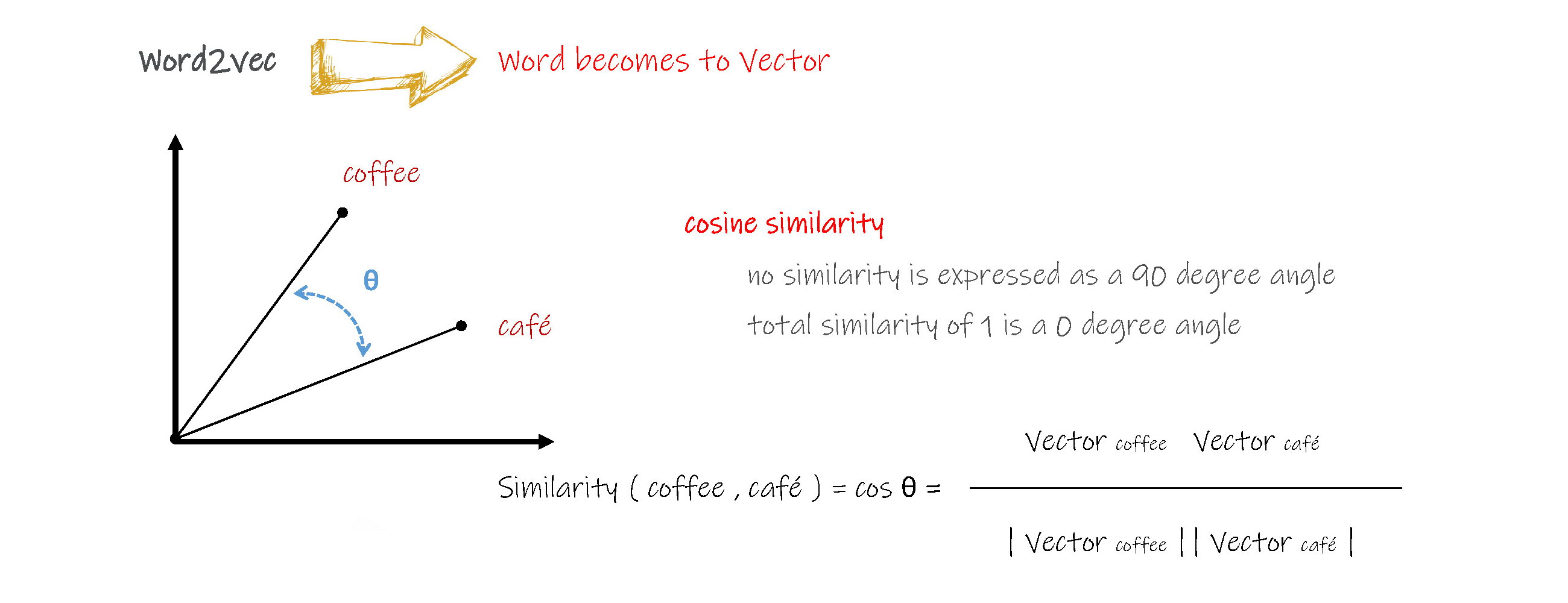
Word2Vec is a word transformer into a vector.
Usually, words that don't occur at least twice in the texts making up the corpus typically aren’t included; otherwise, the vocabulary would be too large.
A word embedding is a matrix of weights, with a row for each word/token in the vocabulary Matrix dot product multiplication with one-hot encoded vector outputs a row of the matrix representing activations from that word. It is essentially a row lookup in the matrix and is computationally more efficient to do that, and this is called an embedding lookup.
Using the vector from the word embedding helps prevent the resulting activations from being very sparse. As if the input was the one-hot encoded vector, which is all zeros apart from one element, the majority of the activations would also be zero. This would then be difficult to train.
Word embedding is one of the most famous representations of document vocabulary. It is capable of capturing the context of a word in a document, semantic and syntactic similarity, relation with other words, etc.
Word2Vec is one of the most popular technique to learn word embeddings using a shallow neural network.
For example, in Camellia teaches English in Camellia Café. , we could get:
Camellia [ 1 , 0 , 0 , 0 , 0 ]
teaches [ 0 , 1 , 0 , 0 , 0 ]
English [ 0 , 0 , 1 , 0 , 0 ]
in [ 0 , 0 , 0 , 1 , 0 ]
Café [ 0 , 0 , 0 , 0 , 1 ]
Because words are discrete states like the other data mentioned above, and we are merely looking for the transitional probabilities between those states: the likelihood that they will co-occur.
The purpose and usefulness of Word2vec is to group the vectors of similar words in vectorspace. That is, it detects similarities mathematically. Word2vec creates vectors that are distributed numerical representations of word features, features such as the context of individual words. It does so without human intervention.
Given enough data, usage and contexts, Word2vec can make highly accurate guesses about a word's meaning based on past appearances. Those guesses can be used to establish a word's association with other words, or cluster documents and classify them by topic. Those clusters can form the basis of search, sentiment analysis and recommendations in such diverse fields as scientific research, legal discovery, e-commerce and customer relationship management.
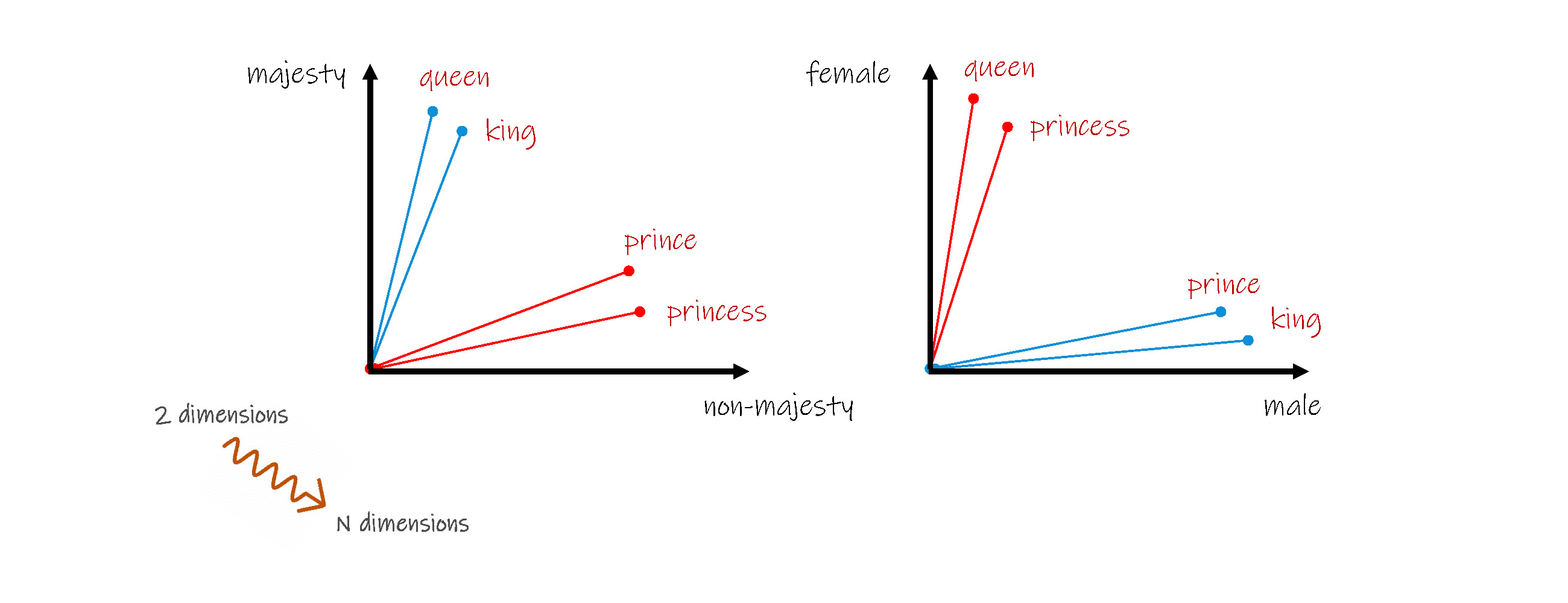
From above, can we get that king - man + woman = queen ?
Measuring Cosine Similarity, no similarity is expressed as a 90-degree angle, while the total similarity of 1 is a 0-degree angle, complete overlap.
Based on Cosine Similarity, we could get when coffee = 1 :
café = 0.8903,
Espresso = 0.9812,
Cappuccino = 0.9105,
Mocha = 0.9125,
Macchiato = 0.9035,
Americano = 0.9635,
……
Model of Sentences
The process of modelling a sentence is just assigning a sentence or words in this sentence with probabilistic value.
N-Gram
This is the simplest way of modelling a sentence. It includes assigning probabilities to sentences and sequences of words. Such as P ( Camellia loves cute bears ) is the probabilistic value of the sentence, and P( bears | Camellia loves cute ) is the probabilistic value of "bear" in the sentence.
Probabilities are essential in any task in which we have to identify words in noisy, ambiguous input, like speech recognition or handwriting recognition. In spelling correction, we need to find and correct spelling errors. Assigning probabilities to sequences of words is also essential in machine translation. Probabilities are also crucial for augmentative communication systems. Word prediction can be used to suggest likely words for the menu.
An N-gram is a sequence of N words: a 2-gram (or bigram) is a two-word sequence of words, and a 3-gram (or trigram) is a three-word sequence of words.
We use N-gram models to estimate the probability of the last word of an N-gram given the previous words, and also to assign probabilities to entire sequences.
Context-Free Grammars
At one level of description, a natural language is a set of strings – finite sequences of words, morphemes, phonemes, or whatever. Regarding this, a large part of language structures can be modelled using context-free descriptions. For that reason, context-free grammars have become a significant means in the analysis of natural language phenomena.

The basic idea of this way is to use variables to stand for sets of strings (i.e., languages). These variable are defined recursively in terms of one another. Recursive rules (productions) involve only concatenation. Alternative rules for a variable allow the union.
We derive strings in the language of a Context-Free Grammar by starting with the start symbol and repeatedly replacing some variable by one of its productions. Any string of variables and/or terminals derived from the start symbol is called a sentential form.
Start symbol: the variable whose language is the one being defined.
Variables (nonterminals): a definite set of other symbols, each of which represents a language.
Terminals: symbols of the alphabet of the language being defined.
Parse trees are trees labelled by symbols of a particular Context-Free Grammar.
Leaves: labelled by a terminal or an interior node (variable). Children are labelled by a production for the parent.
Root: must be labelled by the start symbol.
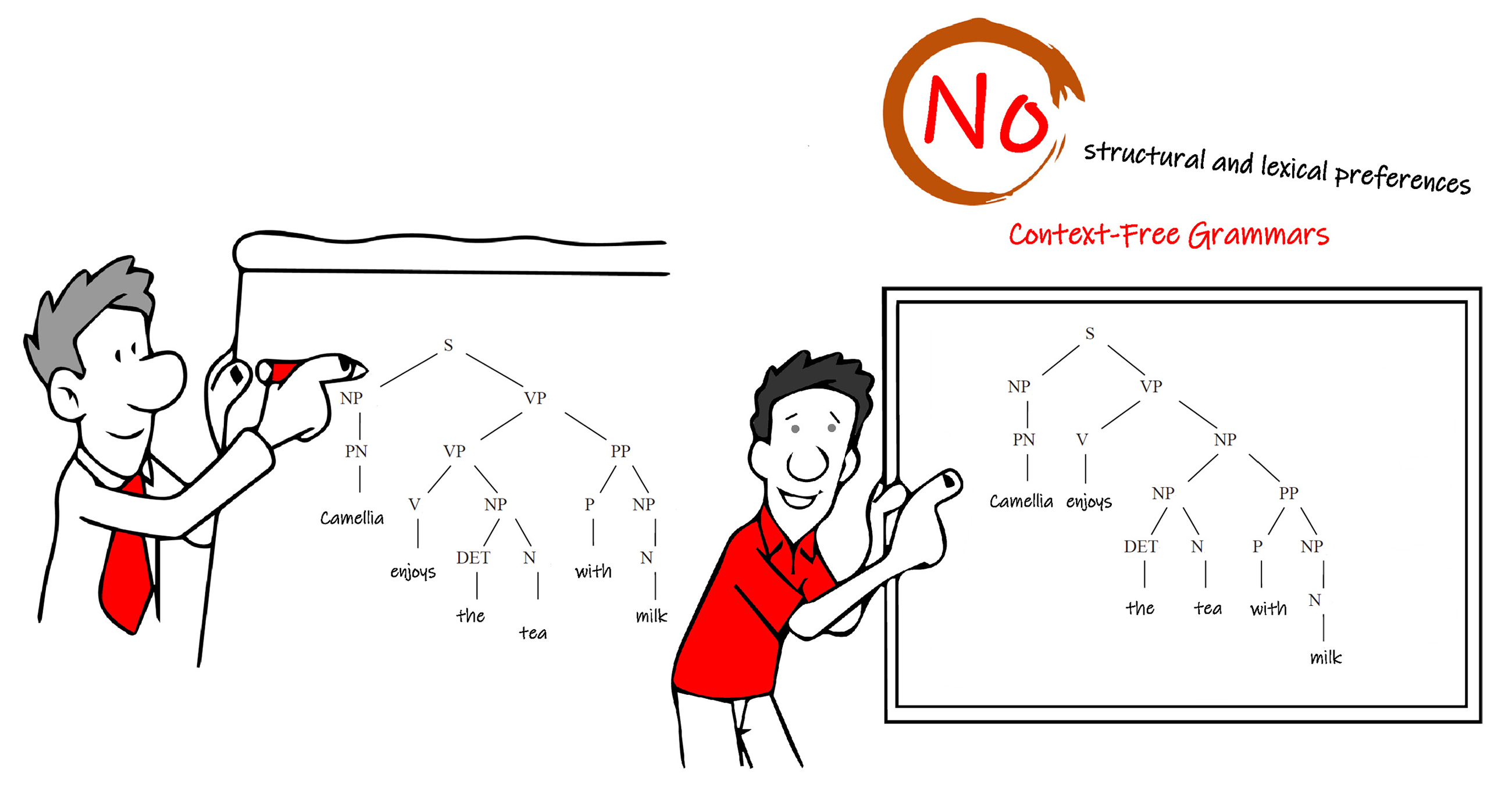
However, if there were ambiguities in the sentence, the grammar would assign multiple analyses, without defining preferences for the ambiguous readings.
For example, in the sentence " Camellia enjoys the tea with milk. ":
We get a meaning of Camellia is drinking tea and milk with two separate cups or glasses, which is shown in the left part of the above figure.
Furthermore we also get a meaning of Camellia enjoys British Style tea, that is drinking tea with milk in the same cup. This is showed in the right part of the above figure.
Probabilistic Context-Free Grammars
Probabilistic Context-Free Grammars are an extension of context-free grammars which model favourite aspects of natural language by adding probabilities to the grammar rules.
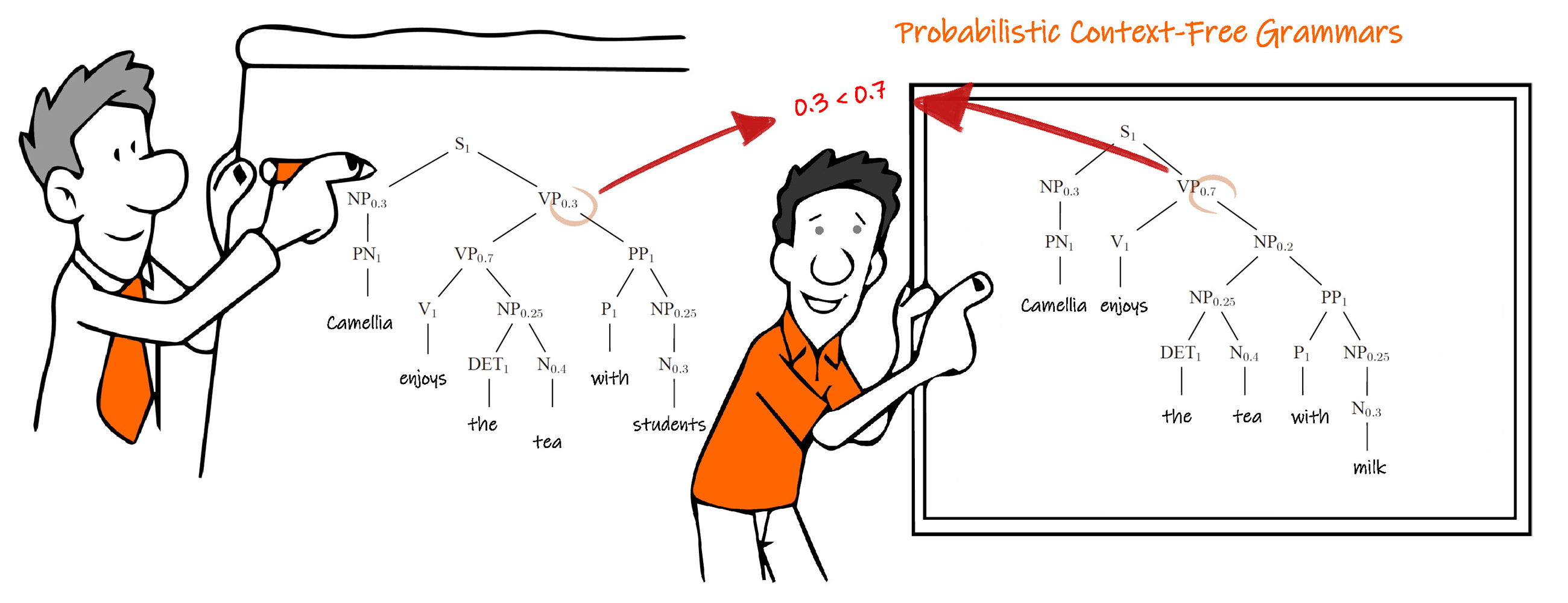
Also, in the sentence " Camellia enjoys the tea with milk. ", we show a Probabilistic Context-Free Grammars model in the above figure.
Nevertheless, Probabilistic Context-Free Grammars fails when it comes to lexically sensitive phenomena or selection preferences of individual verbs since they are based purely on structural factors.
Head-Lexicalised Probabilistic Context-Free Grammars
By incorporating the lexical head of each rule into the grammar parameters, we get Head-Lexicalised Probabilistic Context-Free Grammars.
The lexicalization step has replaced non-terminals with new non-terminals that include lexical items. Once the head of each context-free rule has been identified, lexical information can be propagated bottom-up through parse trees in the treebank. Non-terminals higher in the tree receive the lexical item from their head child. The remaining question is how to identify heads. Ideally, the head of each rule would be annotated in the treebank in practice; however, these annotations are often not present. Instead, researchers have generally used a simple set of rules to identify the head of each context-free rule automatically.
The rules are relatively heuristic but rely on some linguistic guidance on what the head of a rule should be: despite their simplicity, they work quite well in practice.

Now, P(s) is no longer 1, but P( S, lexical item ), which is less than 1. And P( non terminal, lexical item ) = P( non terminal ) x P(lexical item ). The lexical item will affect the Probabilistic value.
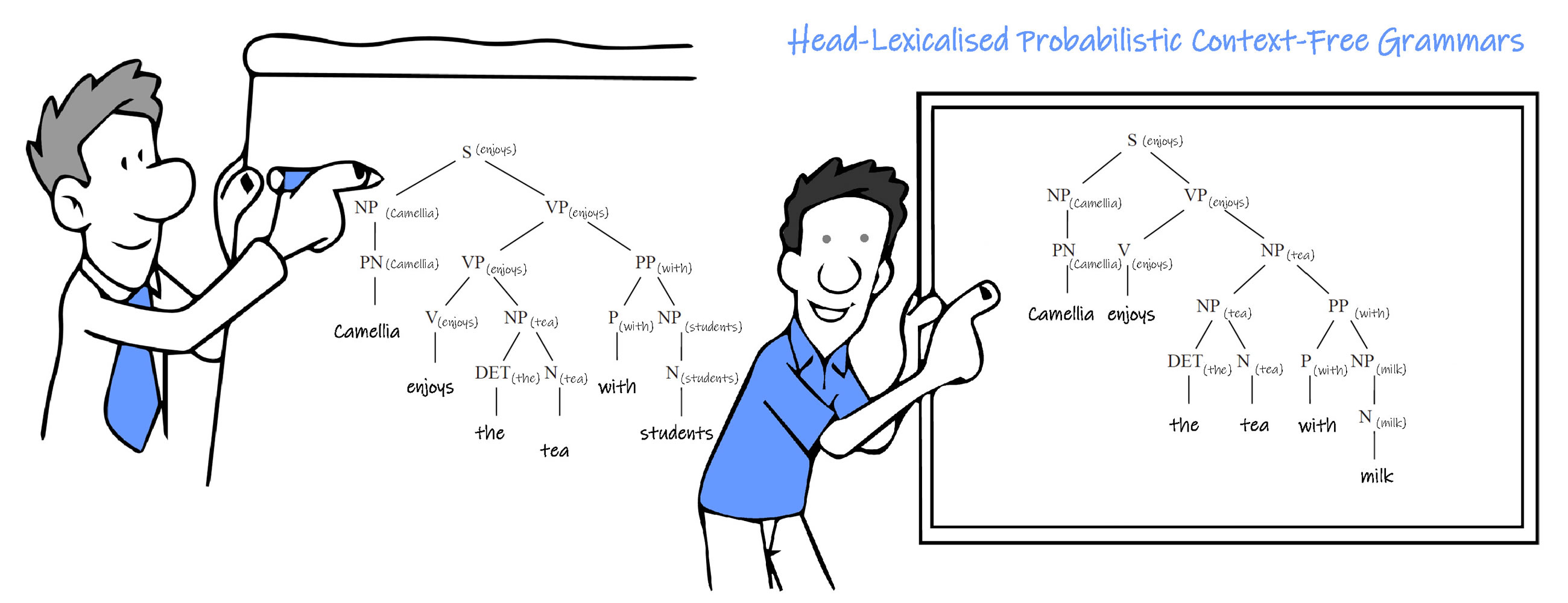
Semi-Supervise Machine Learning is suitable for this type of model.
Chicken-and-Egg Problem
Ultimately, most natural language processing systems need to be able to choose a single correct parse from the multitude of possible parses through a process of syntactic disambiguation. Practical disambiguation algorithms require statistical, semantic, and contextual knowledge sources that vary in how well they can be integrated into parsing algorithms.
A dynamic programming approaches systematically fill in tables of solutions to sub-problems. When complete, these tables contain the answer to all the sub-problems needed to solve the problem as a whole. In the case of syntactic parsing, these sub-problems represent parse trees for all the constituents detected in the input. The dynamic programming advantage arises from the context-free nature of our grammar rules — once a component has been discovered in a segment of the contribution we can record its presence and make it available for use in any subsequent derivation that might require it. This provides both time and storage efficiencies since subtrees can be looked up in a table, not reanalysed.
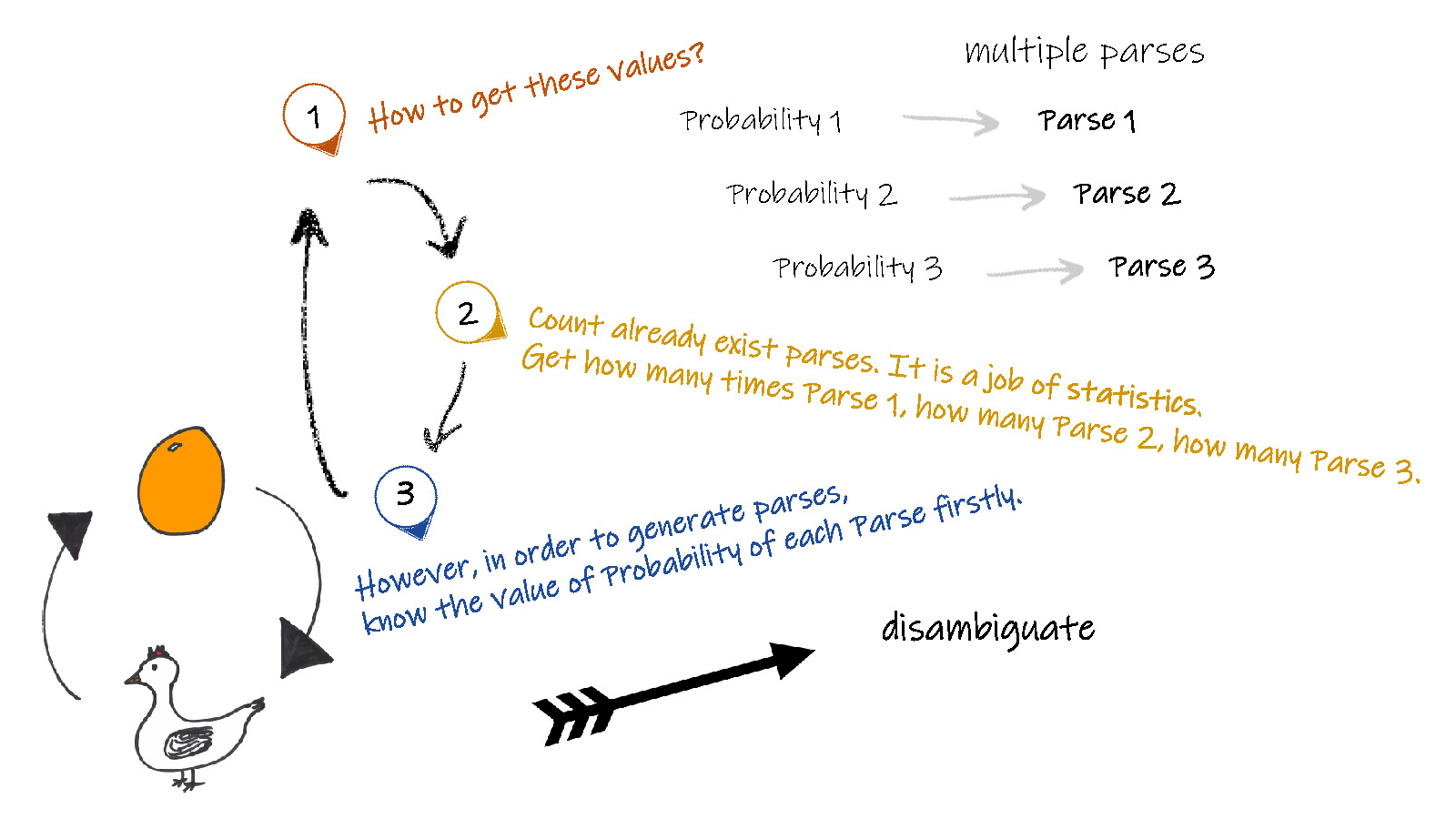
Since most sentences are ambiguous, that is, have multiple parses, we don't know which parse to count the rules in. Instead, we need to keep a separate count for each parse of a sentence and weight each of these partial counts by the probability of the parse it appears in. But to get these parse probabilities to weight the rules, we need to have a probabilistic parser already.
The intuition for solving this chicken-and-egg problem is to incrementally improve our estimates by beginning with a parser with equal rule probabilities, then parse the sentence, compute a probability for each parse, use these probabilities to weight the counts, re-estimate the rule probabilities, and so on, until our probabilities converge.
Natural Language Processing based on Deep Learning
Representation Learning and Deep Neural Network style Machine Learning methods became widespread in natural language processing, due in part to a flurry of results showing that such techniques can achieve state-of-the-art results in many natural language tasks, for example in language modelling, parsing, and many others.
Representation learning is particularly interesting because it provides one way to perform unsupervised and semi-supervised learning. We often have vast amounts of unlabeled training data and relatively little labelled training data. Training with supervised learning techniques on the labelled subset often results in severe overfitting. Semi-supervised learning offers the chance to resolve this overfitting problem by also learning from the unlabeled data. Specifically, we can learn useful representations for the unlabeled data, and then use these representations to solve the supervised learning task.
Deep Learning which is an advanced type of Representation Learning, is using a sophisticated Artificial Neural Network. Above, we have already talked about Feedforward Neural Network, and it is also called Full Connected Neural Network.
Recurrent Neural Networks
A Recurrent Neural Network is essentially a fully connected neural network that contains a refactoring of some of its layers into a loop. That loop is typically an iteration over the addition or concatenation of two inputs, matrix multiplication and a non-linear function.
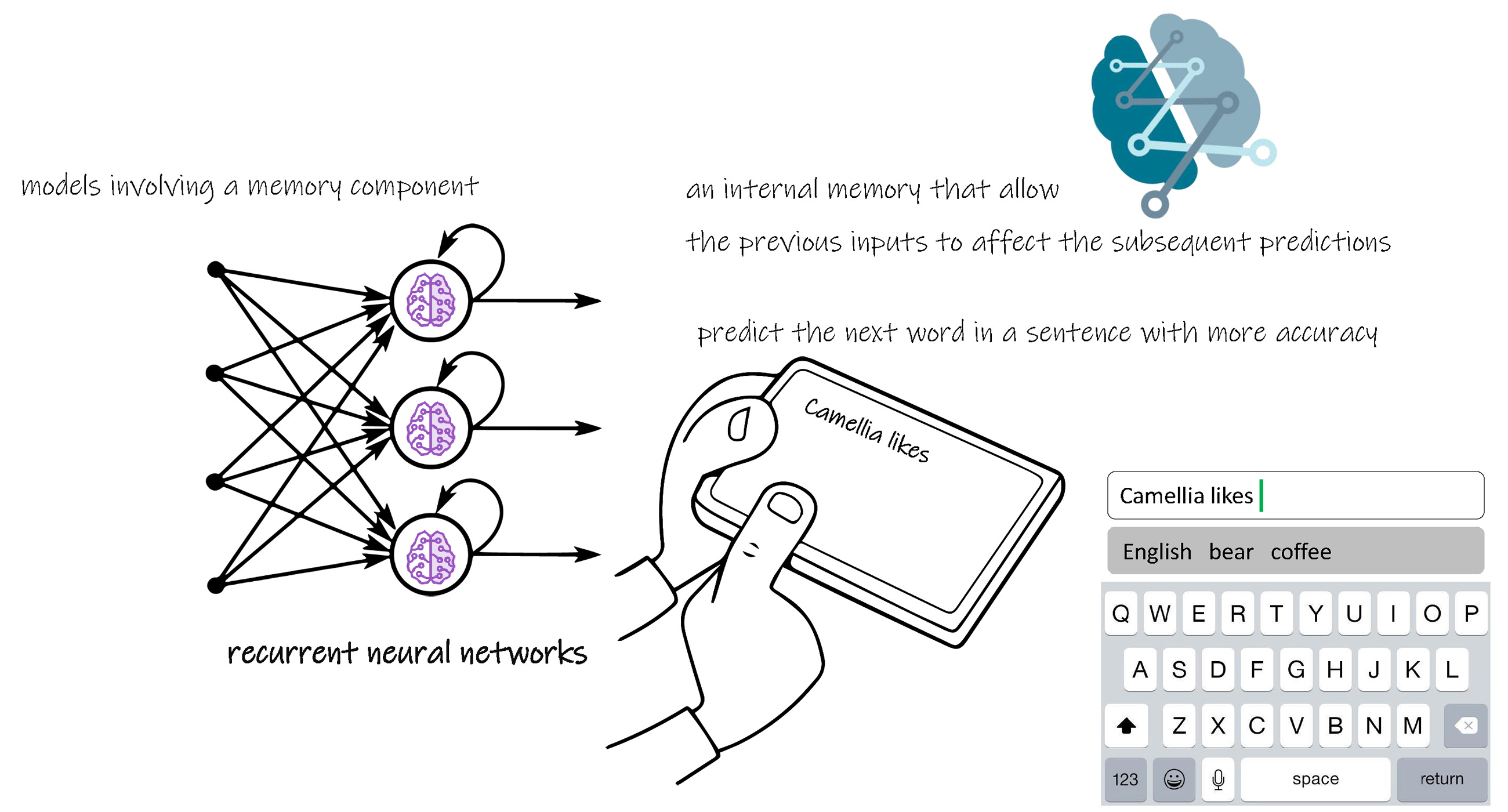
Recurrent Neural Network effectively has an internal memory that allows the previous inputs to affect the subsequent predictions. It's much easier to predict the next word in a sentence with more accuracy if you know what the previous words were.
Just as you are typing the draft for this on your smartphone, the next word suggested by your phone's keyboard will be predicted by a Recurrent Neural Network.
Each iteration of the loop takes an input of a vector representing the next word in the sequence with the output activations from the last iteration. These inputs are added or concatenated together. The output from the last iteration is a representation of the next word in the sentence being put through the previous layer activation function which converts it to a one-hot encoded vector representing a word in the vocabulary.
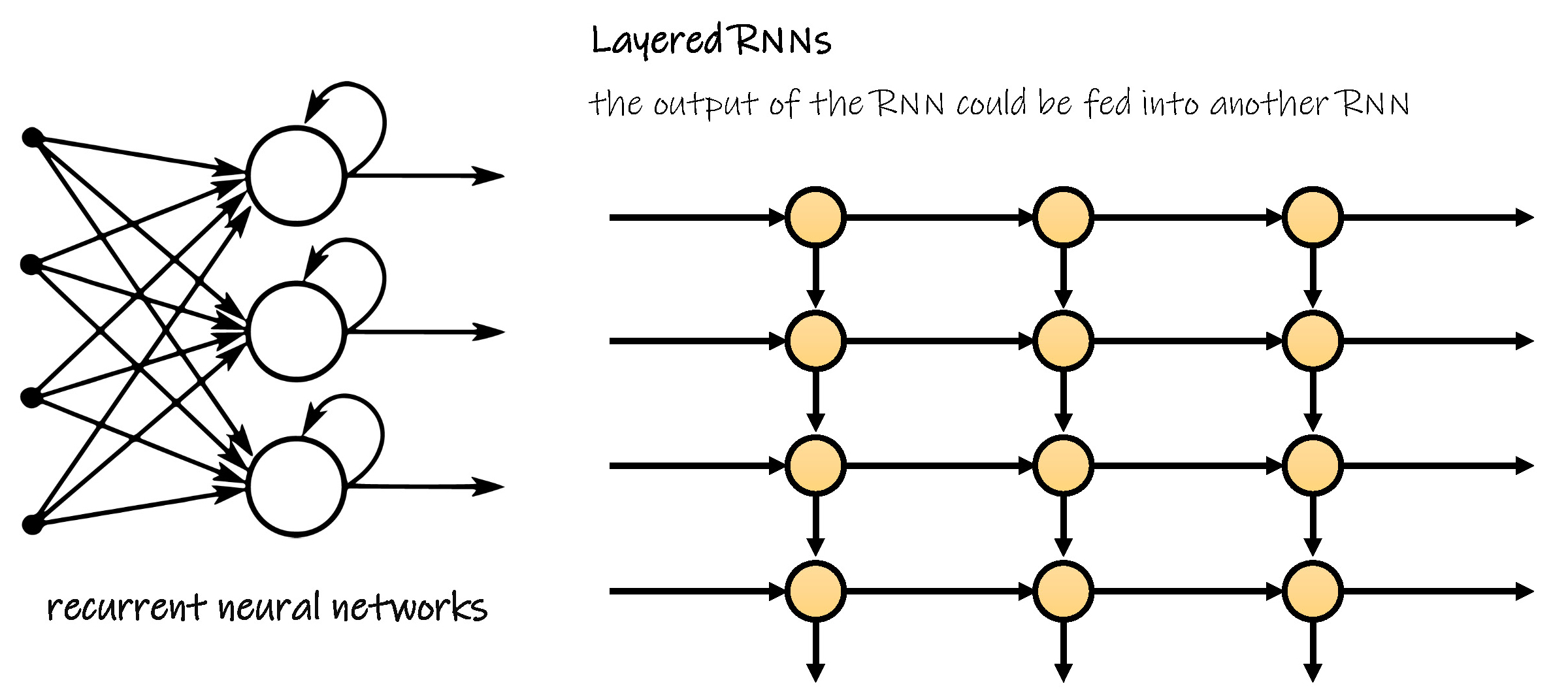
To get more layers of computation to be able to solve or approximate more complex tasks, the output of the Recurrent Neural Network could be fed into another Recurrent Neural Network or any number of layers of a Recurrent Neural Network. The next section explains how this can be done.
However, training this type of Artificial Neural Network is hard: as inputs from may time steps ago can modify the output. Besides, it may cause a vanishing/exploding gradient problem. More recent Input data has a stronger influence on the output. It is unable to learn long term dependencies.

For example, in " Camellia studied in the University of Edinburgh which is in the UK, therefore she speaks fluent Scottish English. ", as Edingburgh is further to Scottish than UK . A standard Recurrent Neural Network may not predict Sottish English , but only English . Thus we could implement a forget-gate and an add-gate to help it to learn when to forget something and when to update internal storage.
In text classification, the prediction of the network is to classify to which group or groups the text belongs. A common use is classifying if the sentiment of a piece of text is positive or negative. If a Recurrent Neural Network is trained to predict text from a corpus within a given domain as in the Recurrent Neural Network explanation earlier in this article, it is close to ideal to be re-purposed for text classification within that domain.
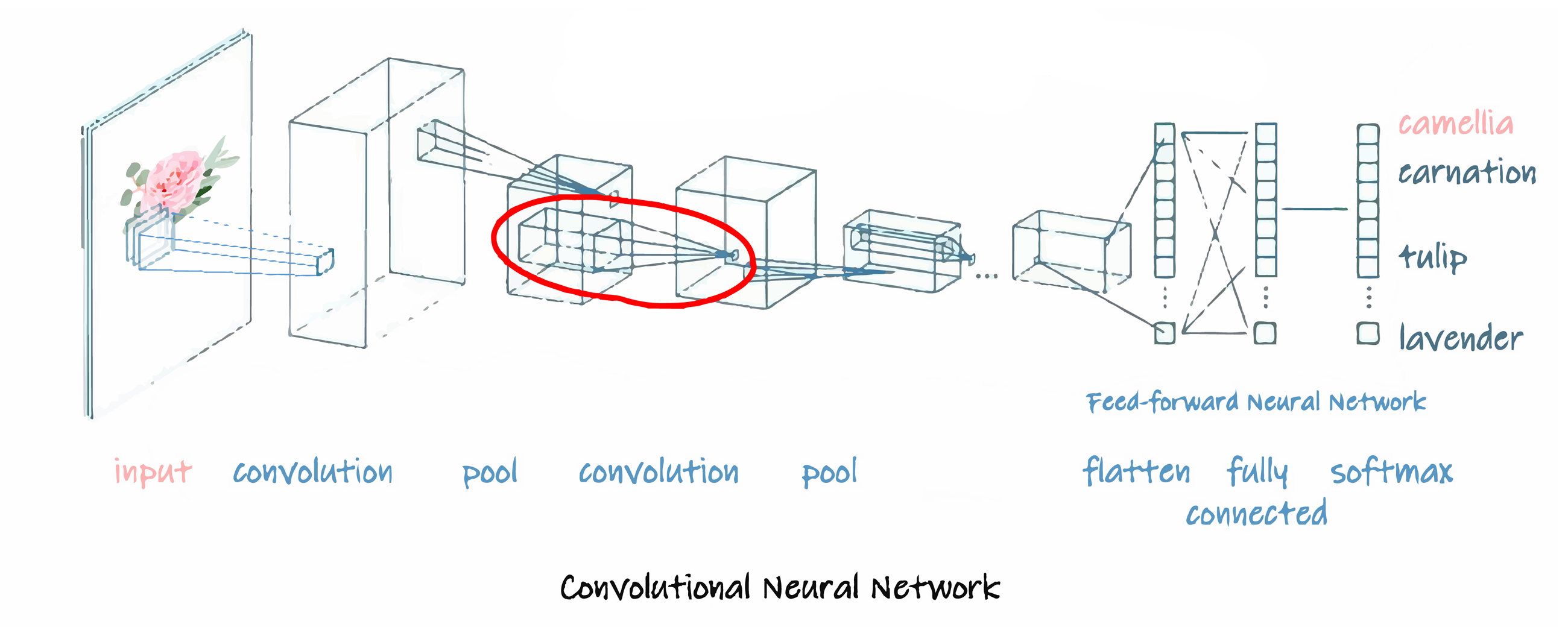
Convolutional Neural Networks
In mathematics, Convolution is a mathematical operation on two functions (f and g) that produces a third function expressing how the shape of one is modified by the other. The term convolution refers to both the result function and to the process of computing it. It is defined as the integral of the product of the two functions after one is reversed and shifted.
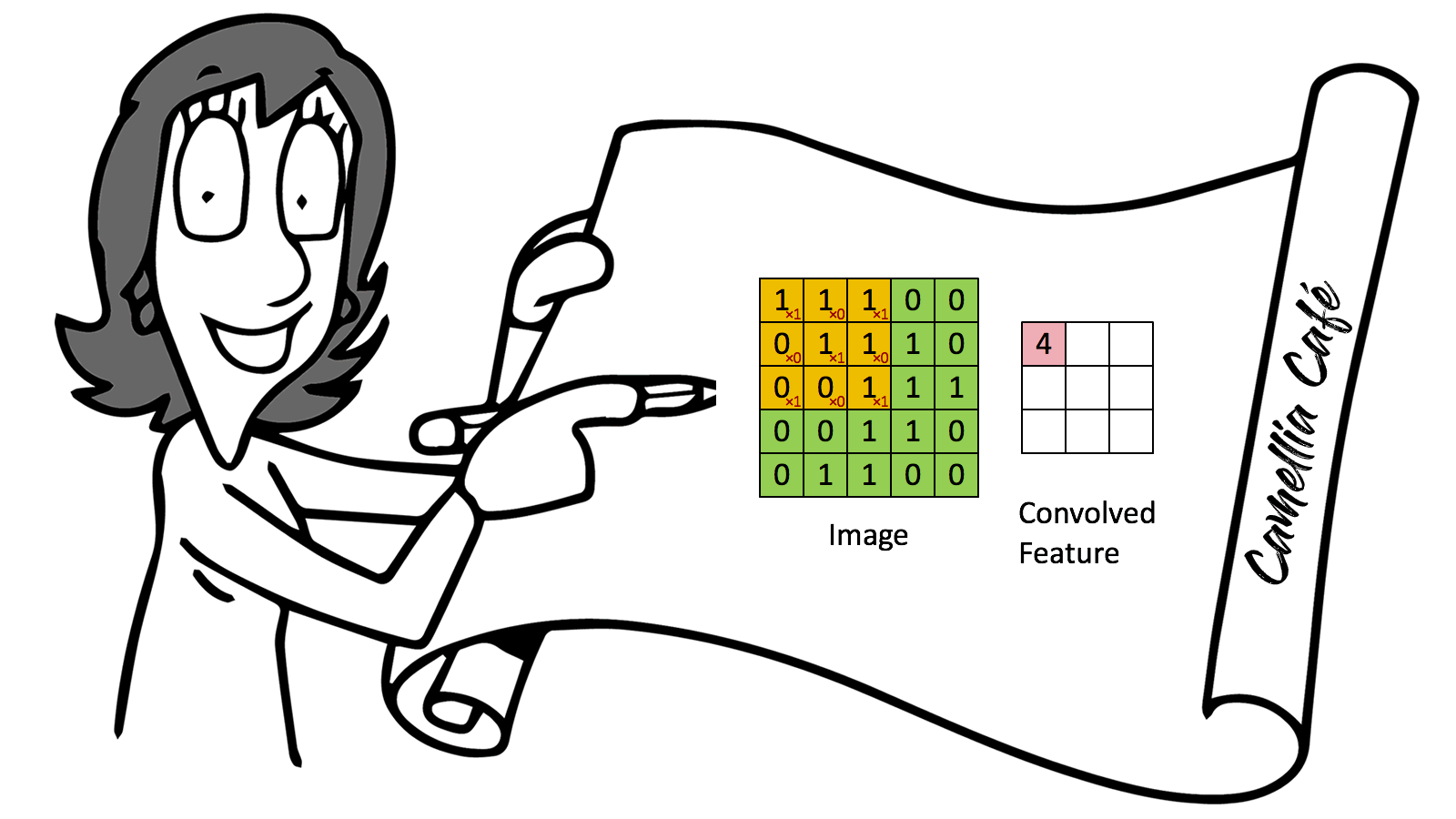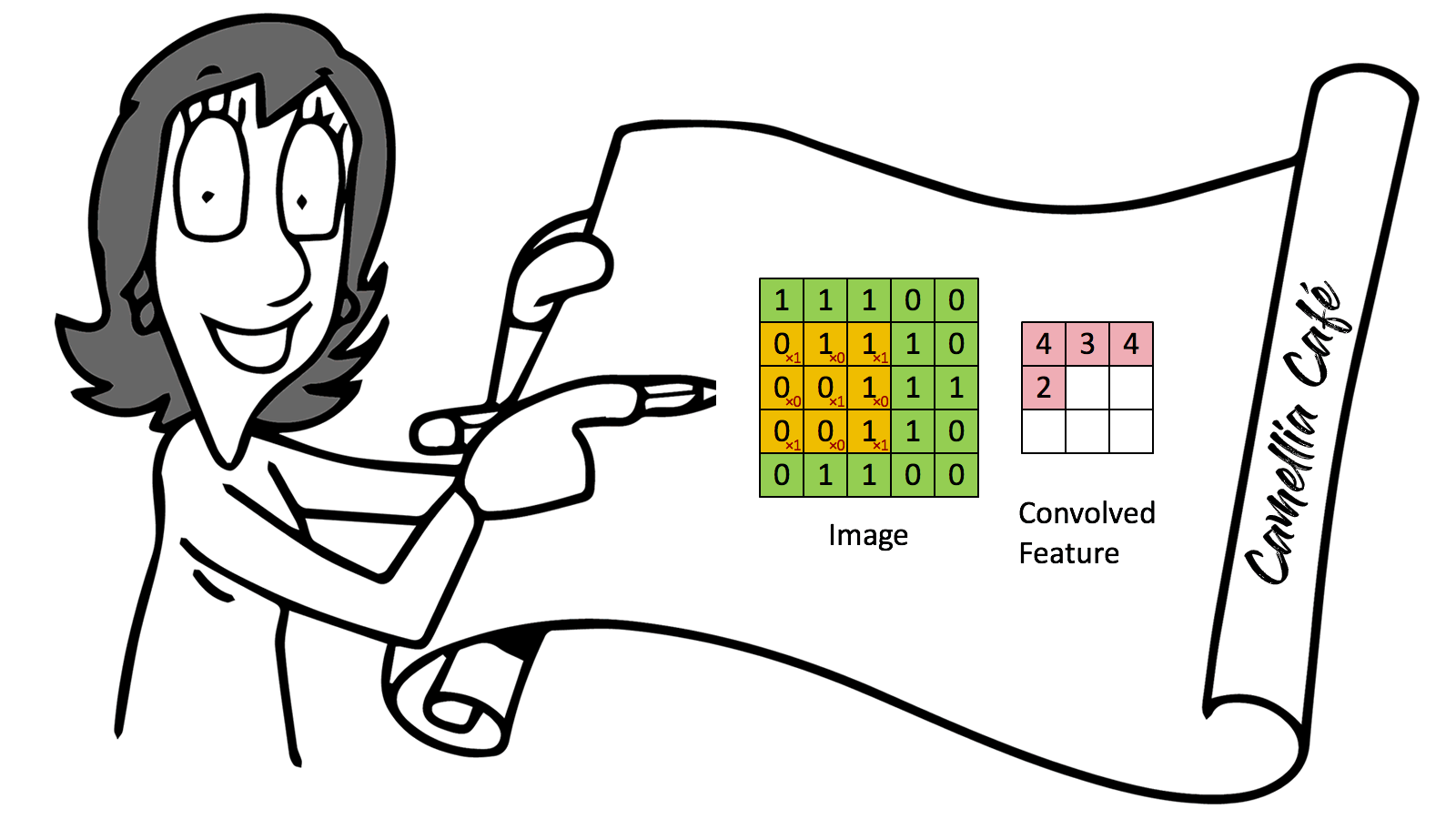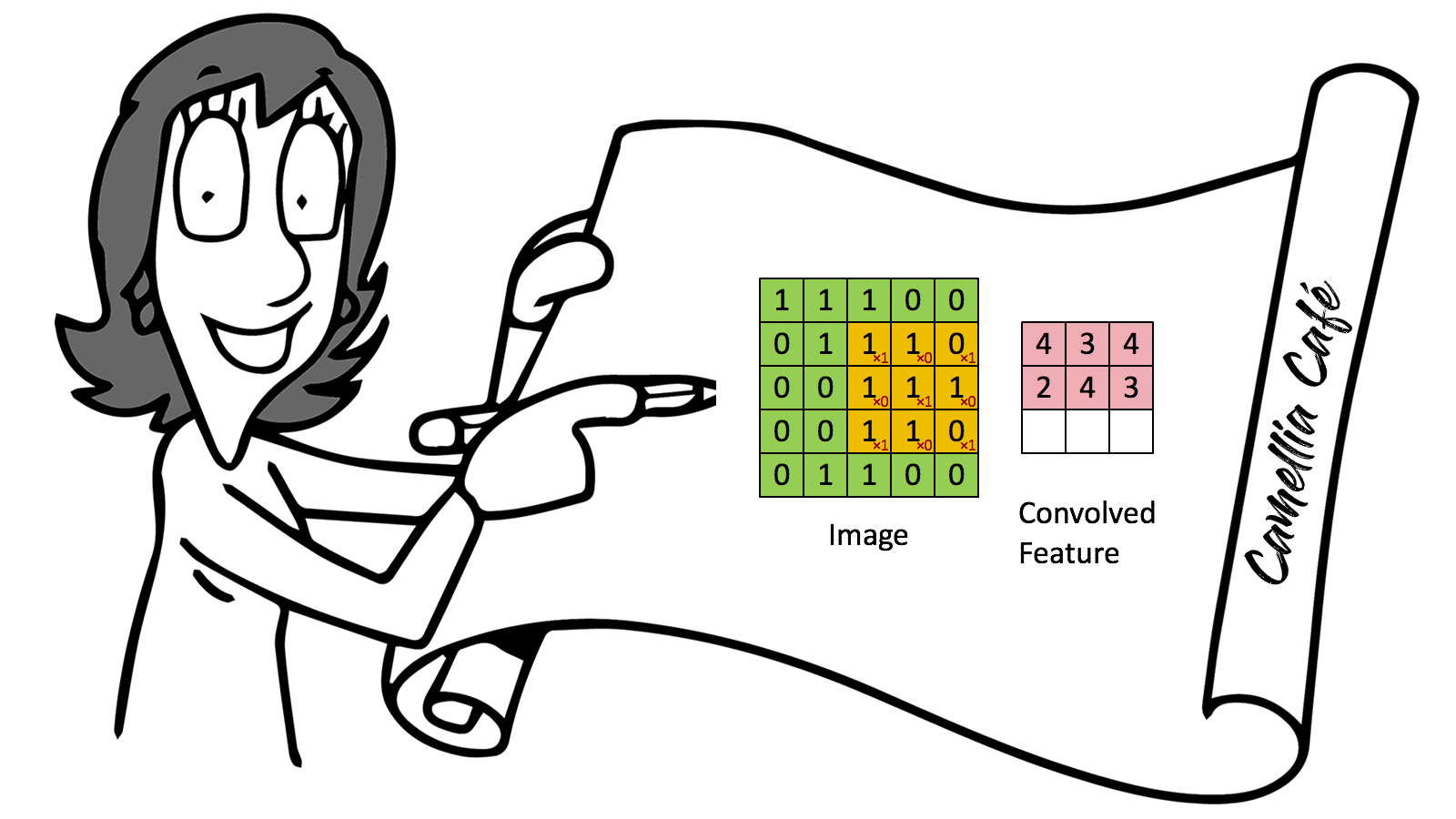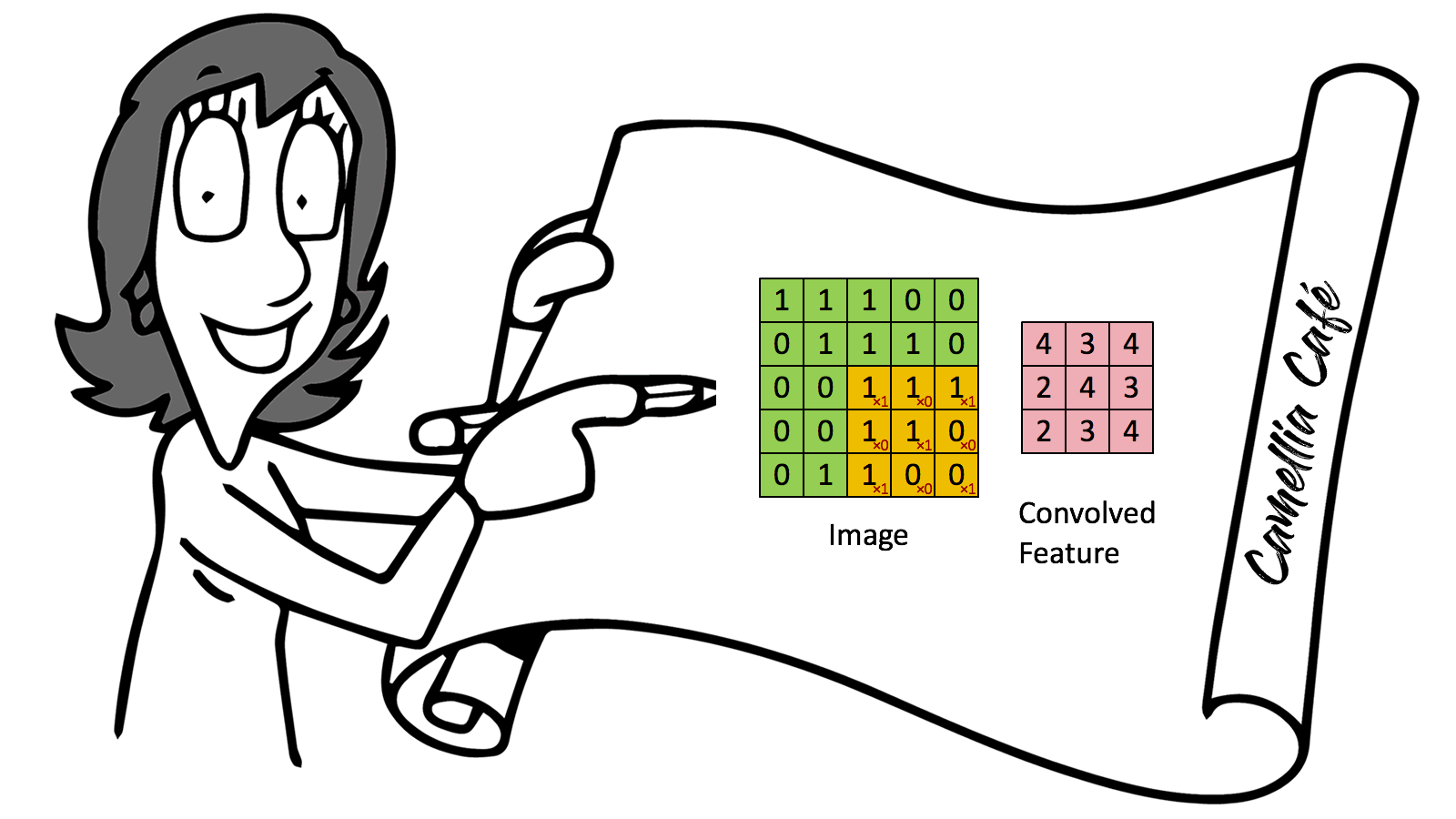
Modern "CONVNETS", as they are often called owe their design to inspirations from biology, group theory, and a healthy dose of experimental tinkering. In addition to their strong predictive performance, Convolutional Neural Networks tend to be computationally efficient, both because they tend to require fewer parameters than dense architectures and also because convolutions are easy to parallelise across GPU cores. As a result, researchers have sought to apply CONVNETS whenever possible, and increasingly they have emerged as credible competitors even on tasks with 1D sequence structure, such as audio, text, and time series analysis. Some clever adaptations of Convolutional Neural Networks have also brought them to bear on graph-structured data and in recommender systems.
The input to most NLP tasks is sentences or documents represented as a matrix. Each row of the matrix corresponds to one token, typically a word, but it could be a character. That is, each row is a vector that represents a word. Usually, these vectors are word embeddings (low-dimensional representations), but they could also be one-hot vectors that index the word into a vocabulary. For a ten words sentence using a 100-dimensional embedding, we would have a 10×100 matrix as our input. That’s our “image”.
1. Sentences or documents are represented as a matrix. Use a Filter to do Convolution operation with this matrix. The stride of filter operation can be one or more steps.

2. Pooling, which selects one typical value from the result of Convolution.
3. Convoluting and Pooling again.
...
4. Keep in mind when in Step 1 and Step 3, we could use more than one Filter or different Filters; thus, we could get a lot of Convolution results, which constitute a cubic.


5. As we use more than one Filter, Pooling also generates more than one value. We need to put all these values into a Feedforward Neural Network. This is called Flatten.
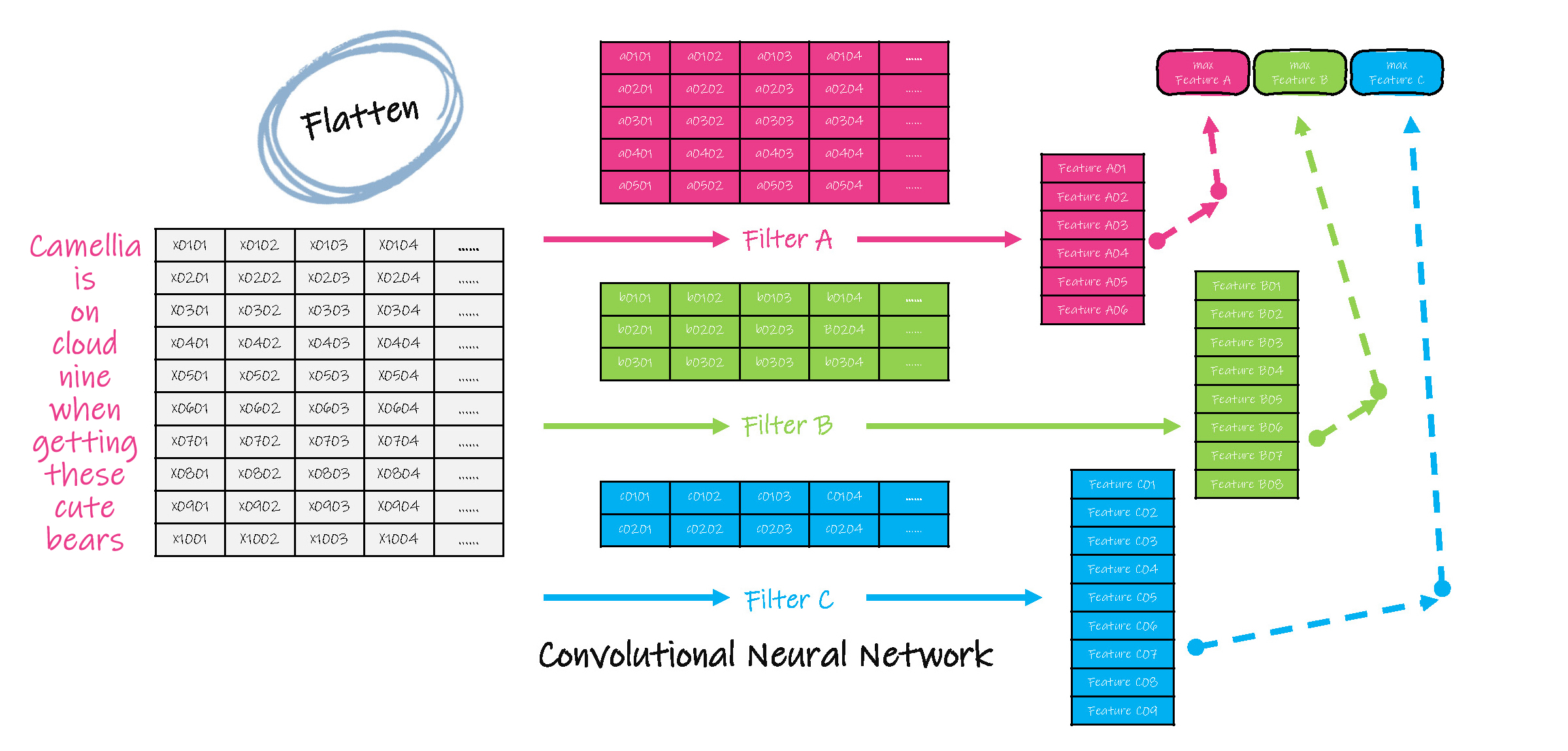
6. Just use this Feedforward Neural Network to get the final output.

The same to analyse a text, each sentence in the text can be modelled by the above steps. That means the cubic becomes an N dimension matrix.
The most natural fit for Convolutional Neural Networks dimension to be classifications tasks, such as Sentiment Analysis, Spam Detection or Topic Categorization.
During the training phase, a Convolutional Neural Network automatically learns the Values of its Filters and Weights based on the task we want to perform.

Now we have already used a Convolutional Neural Network to analyse photos and texts. A Convolutional Neural Network could do more than we think. It is useful in voice configuration.
There are more Artificial Neural Networks and Deep Learning Technologies in Natural Language Processing.
The Gray Modelling Box
The Machine Learning or Deep Learning using a sophisticated Artificial Neural Network, are called Black Modelling Box, which we will not see its inter. While a model based on Hand-Written Rules are White or Trasmparent Modelling Box as we know the detail inside it.
A Black Modelling Box need sample data to learn. It releases a great job done by our human. But the key is that the sample data should be vast and diverse.
A White Modelling Box is more accurate, but it is a massive work done by Human. Sometimes, it even not feasible to fulfilment.
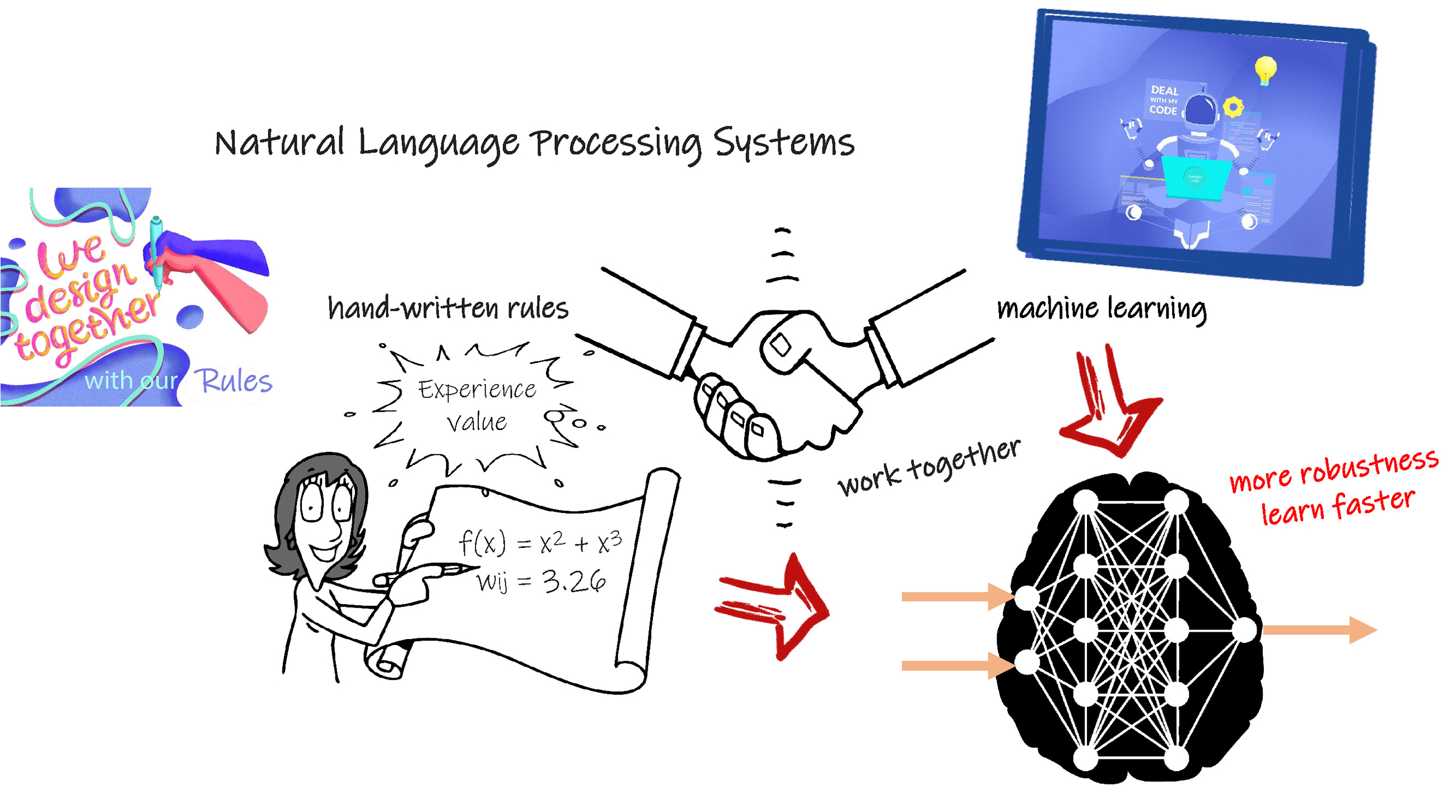
The Gray Modelling Box combine Machine Learning and hand-Written Rules. It is not only used in Model, but also during the process of Deep Learning. If you already get some knowledge, it will speed up modelling.
Hardware
Hardware is the foundation of Artificial Neural Networks and Deep Learning Technologies.
1. CPU, GPU and TPU, which help us to perform calculations of algorithms, is the core of modelling and learning.
2. With high capacity Memory and Cloud Storage, we can collect an extensive sample and data.
3. How to input Natural Language into Artificial Intelligence Machines and make the output from them? Just using microphone to capture sounds, using cameras and video recorders to record image and footages, using stereos to making sounds ... Smart Mobile Phones and Internet of Things give a significant hand in information collection at any time anywhere.
4. Wi-Fi, Bluetooth, 5G and other communication technologies give a fast and convenient way for information transfer.
Chips
We are familiar with CPU (Central Processing Unit) and GPU (Graphics Processing Unit). Typically, GPUs are widely used in Graphics Processing. Why do we use GPUs in Natural Language Processing more and more?
A CPU has the advantage of Low-latency, while a GPU has High Throughput;
A CPU is good at calculating long instructions, while a GPU is skilful in calculating parallelly;
A GPU has more Cores than a CPU, while a CPU has more Memory Units.
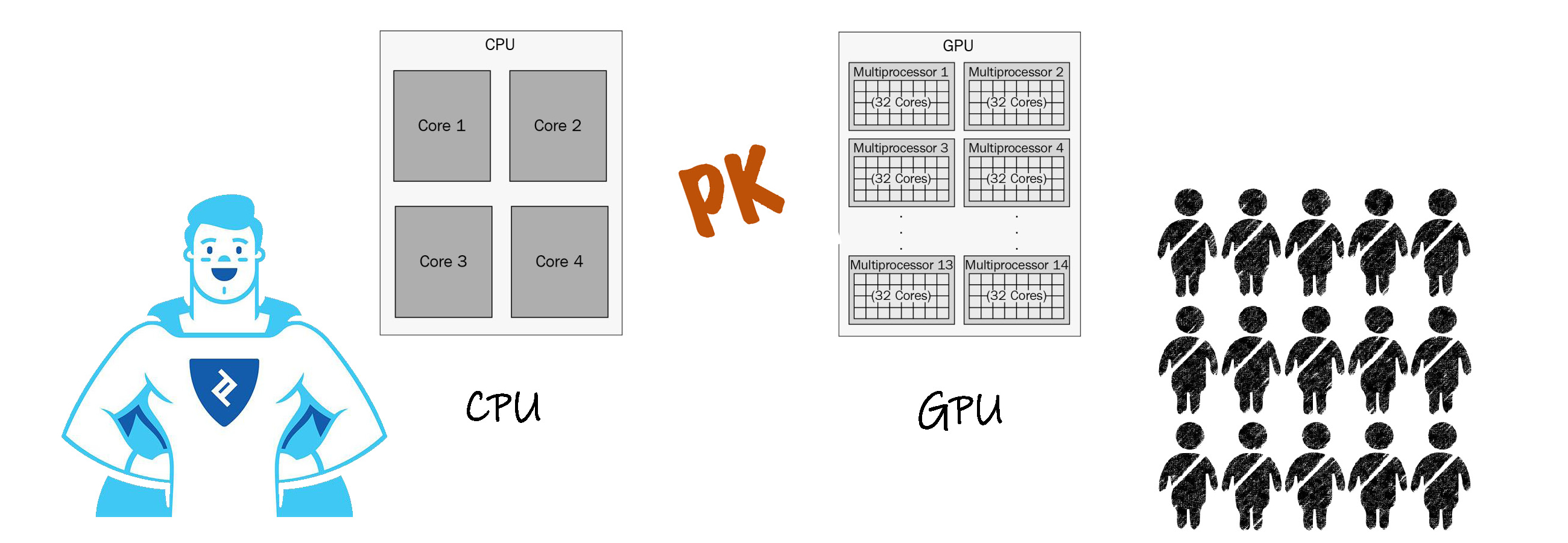
Reading the above figure, you maybe see that a CPU is a superman and a GPU is a groud of engineers.
As there are multi-input and multi-output in a sophisticate Artificial Neural Network, a GPU could do a great job as its instinct of parallel calculation.
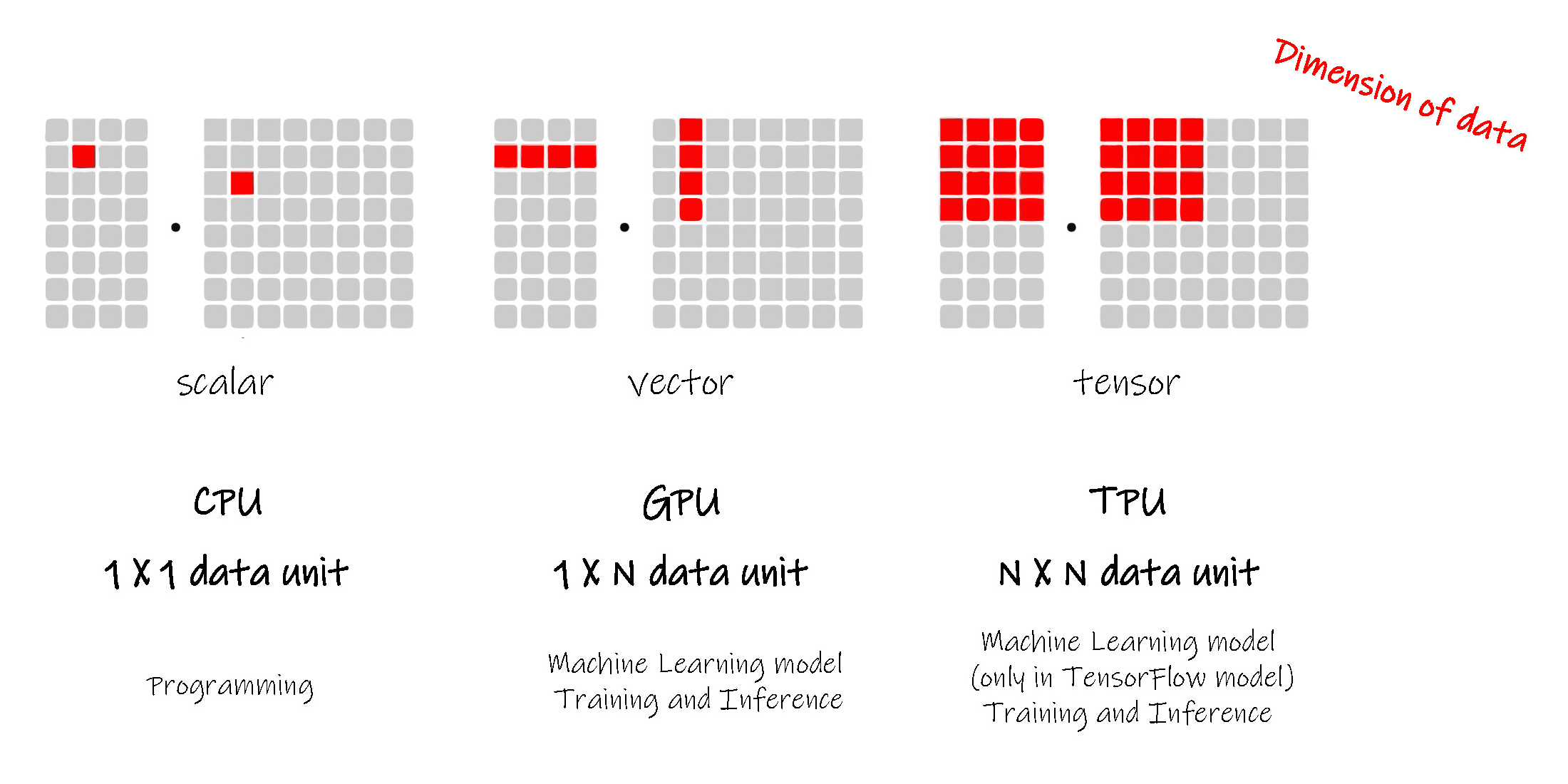
More, a TPU ( Tensor Processing Unit ) adds Cores based on a GPU, but each Core maybe not stronger than it in a GPU. Thus a TPU could do tasks with more dimension matrix.
Wireless Communication
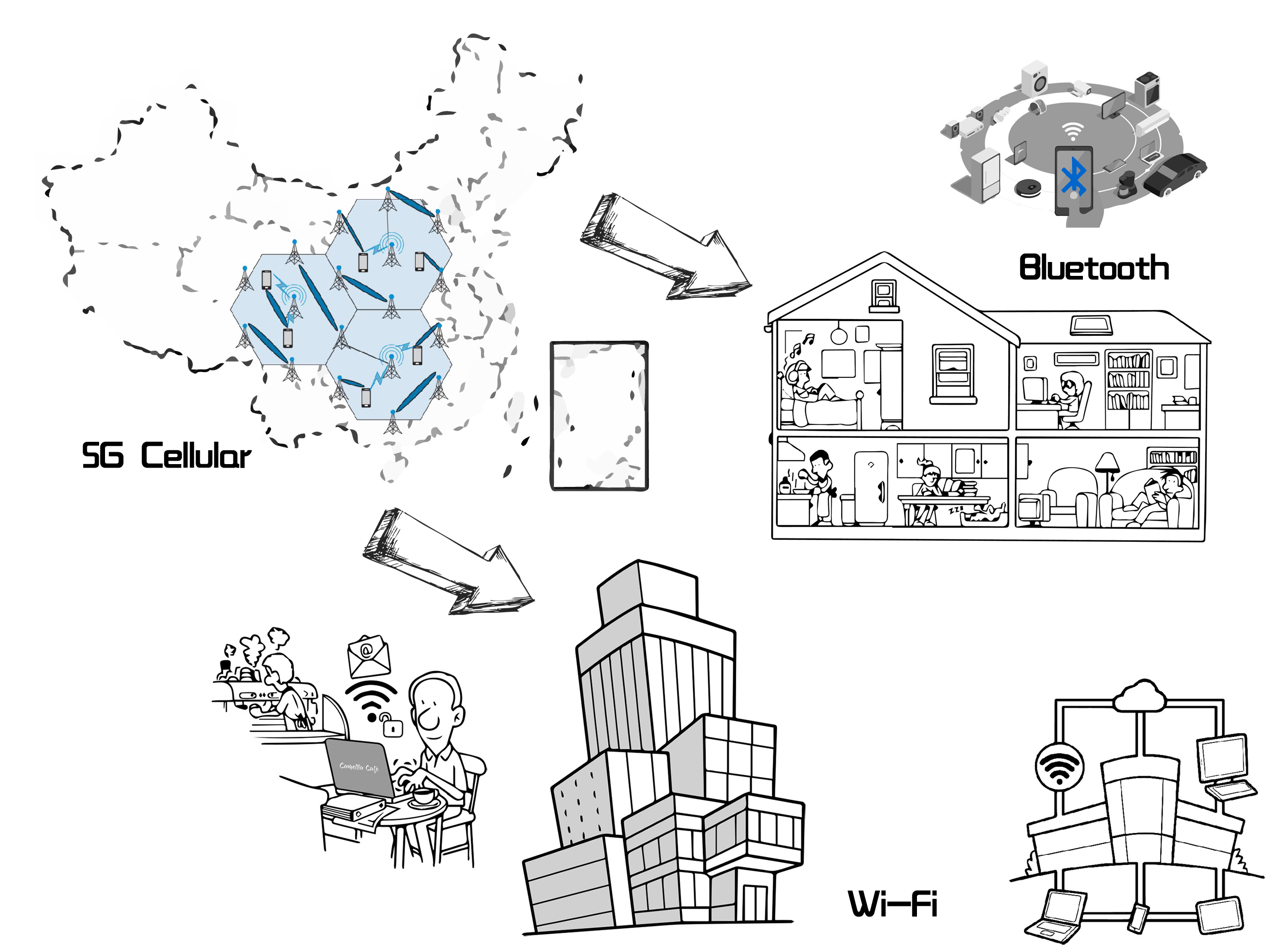
Wi-Fi, Bluetooth and 5G are communication technology using wireless way.
5G has a pervasive operating area. It usually covers a whole country or an area. Typically, the carrier needs to be authorised by the government to build its communication band. Compared with 4G technology, the 5G has high frequency, 24-86GHz, and short wave. Thus the carrier must build more base stations to overcome the problem of weak transfering of the short wave signal.
Wi-Fi's working scope is relatively smaller, only in an office or in a building. The signal is modulated into 2.4GHz.
Bluetooth is used for connecting smart devices only in a house. The signal is also 2.4GHz.
Quantum Mechanics

In the past years, Moore's Law is hard to perform due to the chock point of heat dissipation. Thus the manufacturer could not produce more and more transistor in nanochips. Quantum Mechanics Technology has been developed so quickly, and we will have new material such as Topological insulator, and new type computers such as Quantum Computers in the coming several years. Both increase the power of Artificial Intelligence Machines.
Instinct Intelligence
Now we have introduced a lot of Artificial Intelligence Technology of Natural Language Processing, but all are limited technologies. They only fulfil the cognition but not include real think. How to make an Artificial Intelligence Machine speak, read, write and listen as our human? This is an issue of making a more advanced Artificial Intelligence Technology. Jus we know, a human has multi intelligences. Why do we not use other intelligences to help the Linguistic Intelligence of an Artificial Intelligence Machine?
If we could do it, Artificial Intelligence Machines is a real intelligent machine. Moreover, we will call them he or she, not it.

Logic/Mathematical helps Linguistics Intelligence
Everything must be based on Mathematics. Just build an excellent algorithm.
Music/Musical helps Linguistics Intelligence
Use Phonetics and Phonology Technology.
Let the Artificial Intelligence Machine listen to and follow a human performer so it can respond in synchrony. Also, let it be a generator of ideas that might nudge a songwriter out of their melodic comfort zone into somewhere a bit more interesting.
Develop a text-based, cross-platform language that allows real-time synthesis, composition, performance and analysis of music.
Picture/Spatial helps Linguistics Intelligence
Recognise words with different fonts from pictures or photos using Optical Character Recognition Technology.
Body/Bodily-Kinesthetic helps Linguistics Intelligence
Express different Context by the aid of Sign Language or Body Language.
Nature/Naturalist helps Linguistics Intelligence
Language meaning relies on the place, time … Recognise Atmosphere, Geography, Astronomy, Animal, Botany … to get the Pragmatics.
People/Interpersonal helps Linguistics Intelligence
Negotiation of meaning between speaker and listener.
Get feedback from the audience.
Self/Intrapersonal helps Linguistics Intelligence
Be aware of and understand the machine itself. Learn, Update itself by itself. This is Un-Supervise Learning.
Life/Existential helps Linguistics Intelligence
Make Artificial Intelligence Machines think more deeply about its life.
Let them know they have done an excellent job, so human prefer to use them. The more be used, they get more data. Thus they will learn more and do better.
Moral helps Linguistics Intelligence
An Artificial Intelligence Machine shall read fables and learn mottos. It shall get the meaning inside words, then write and speak out. It shall have a right working attitude and responsible. Furthermore, this should be gotten by itself. That means it knows:
" If I don’t know this word, I will learn. If my translation were wrong, I would Update. "
Turing Test
Why is this ridiculous?
One, ask humans to simulate individual operations on a computer chip manually and finds humans perform about 0.01 MIPS.
The other, ask computers to simulate individual neurons firing in a human brain and finds humans perform about the equivalent of 50,000,000,000 MIPS.

Alan Mathison Turing is a British Mathematician, Logician and the father of Computer and Artificial Intelligence Technology.
Turing proposed that a human evaluator would judge natural language conversations between a human and a machine designed to generate human-like responses. The evaluator would be aware that one of the two partners in conversation is a machine, and all participants would be separated from one another. If the evaluator cannot reliably tell the machine from the human, the machine is said to have passed the test.
Then, our children will not call an Artificial Intelligence Machine with it, but with he or she. And not we and it, but we together.

